





前回紹介したScispaceですがLiterature reviewの特徴をつかむために、ある程度私が慣れた分野に関して質問を投げかけて、出てきた回答とその問題点を検討してみたいと思います。
なお、Scispaceの公式リンクは以下です。(※アフィリエイトが含まれます)
Scispace

医学の専門的な内容を含むので、非医療従事者の方にも分かるように(できるだけ?)適宜解説を入れていきます。
今回も動画を合わせてあげていますので、記事と同内容になっていますが、動画が良ければこちらもご覧ください。
脳梗塞急性期治療を例にした質問
医学に関する臨床的な疑問を一度投げかけてみようと思います。専門家内でも意見が固まっているものだとあまり意味がないので、ここはひとつ意見が定まってない部分のある内容について聞いてみます。
今回使ってみた質問は「脳梗塞急性期におけるヘパリン使用の有効性について」です。
ここで、なじみのない人のために少し解説を入れます。
脳梗塞は脳の血管が詰まることで起きる病気で、発症直後に血流が届かなくなった脳の部位の症状が起きます。発症後数日~1週間程度は症状が変動することがあるため、早期からそれ以上血流を悪化させないための治療が行われます。
ヘパリンは抗凝固薬と呼ばれる血液を固まりにくくする薬です。一方で、出血を起こしやすくなるため出血性合併症が増えないかという点には注意が必要な薬剤です。これを使うことで症状の悪化や死亡を減らせるか、というところが焦点となります。
さて、医学において病気に薬を使用したらどうなるかは、それが代表的なものであれば、ガイドラインと呼ばれる専門家による協議のうえで決定された指針が公表されています。
というわけで比較対象としてガイドラインをまず見ていこうと思います。
以前から臨床的に使用されていたこともあって、日本の脳卒中ガイドライン2021[改訂2023]では以下のように記載されています1。
脳梗塞急性期に、未分画ヘパリン、低分子ヘパリン(保険適用外)、へパリノイド(保険適用外)を使用することを考慮しても良い(推奨度C エビデンスレベル中)。<脳卒中ガイドライン2021 p.38>
未分画ヘパリンや低分子ヘパリンなど書いてありますが、これらはそれぞれヘパリンの種類です。
ガイドラインの本文ではランダム化比較試験において未分画ヘパリンで14日以内の再発が有意に少なかった点があげられていますが、一方出血による合併症が多い点もあげられています。
「ランダム化比較試験」というのは治療の効果をみるためには必要性が高い試験で、十分な人数や適切な設定がなされれば、結果が重要視されるべき試験であると言えます。
このガイドラインでは、これらの試験で出血性合併症が増加した点や効果が出なかった研究もあることから、欧米のガイドラインではヘパリンの推奨がされていないことも触れられています。
ここでもう一つの対照として2019年のアメリカの代表的なガイドライン(AHA/ASA guideline)をみてみます2。
Anticoagulants(抗凝固薬)の項目では以下のように書かれています。
Urgent anticoagulation, with the goal of preventing early recurrent stroke, halting neurological worsening, or improve outcomes after AIS, is not recommended for treatment of patients with AIS. ※AISはAcute ischemic stroke(急性期脳梗塞)の略です
つまり「急性期脳梗塞において再発予防や症状の悪化、改善のための抗凝固療法は推奨しない」と書いてあります。ここにはヘパリンも含まれています。
その理由として本文ではメタ解析による結果で有効な結果が出なかったことが確認されたことと、非盲検のランダム化比較試験で入院10日以内の悪化は減ったけれど90日後の生活機能については大きな差がなかったことが触れられています。
実際にどちらが正しいかといった議論は主旨から外れるので踏み込みませんが、ここで着目したいのはどちらのガイドラインにおいても、ランダム化比較試験あるいはそれらのメタ解析の論文について主に触れていること。そして、そのアウトカムの重要性を鑑みて最終的な回答を導き出している点です。
結論を先に言ってしまうと、こういった文献のもつ重要性や結果の解釈などの「価値判断」を一次情報の文献のみで行うのは、汎用的な大規模言語モデルでは難しいのではないかと思います。これからそこを見ていきたいと思います。
なお、今回の質問に関して、何を重要視するかは医学分野独自な部分もあるかもしれませんが、どの分野においても「手法の妥当性」や「アウトカムの重要性」はそれぞれ順序があるのではないでしょうか。他の分野であってもやはりそこをAIが判断するには専用のデータセット持ってトレーニングしなければ難しいように思います。
Scispaceで同じ質問を投げかけてみる
では実際にScispaceを使って同じ質問を投げかけてみます。日本語で質問すると用語の部分で解釈がぶれやすいので、英語で質問してみましょう。
質問は直球で「Is heparin effective for the treatment of acute ischemic stroke?」としてみます。
回答は以下のようになりました。
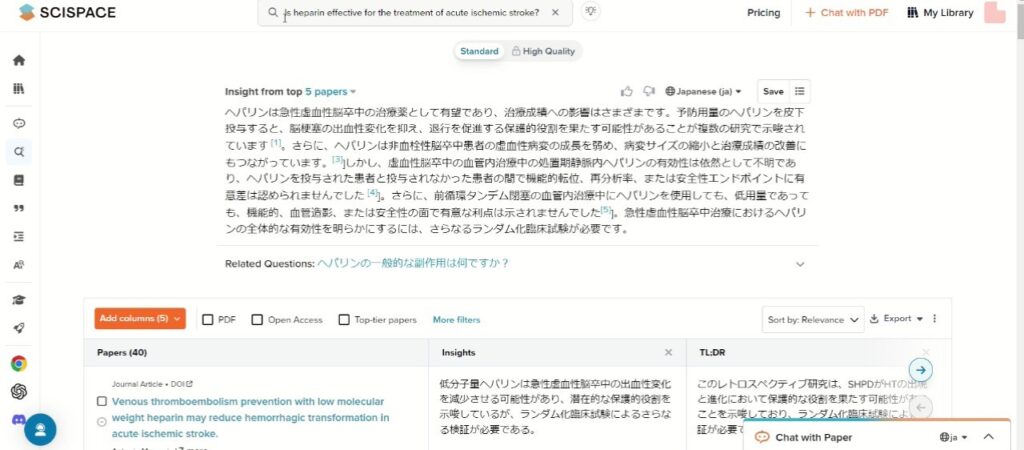
<Scispace(https://typeset.io/)より>
皮下投与のヘパリンについての言及がされ、出血性変化を減少させることが示唆された研究がまず出てきます。ただ、こちらについてはランダム化比較試験ではなく、重要性が高いとは言えません。
続いて提示される研究もカテーテルでの血管内治療とともにヘパリンを投与した際の研究で、本来聞きたかった薬剤での治療効果を問うものとは異なります。こうした患者層の背景情報も明示的に指示しなければ判断が難しいことが分かります。
続いて、引用数によるソートを行ってみます。
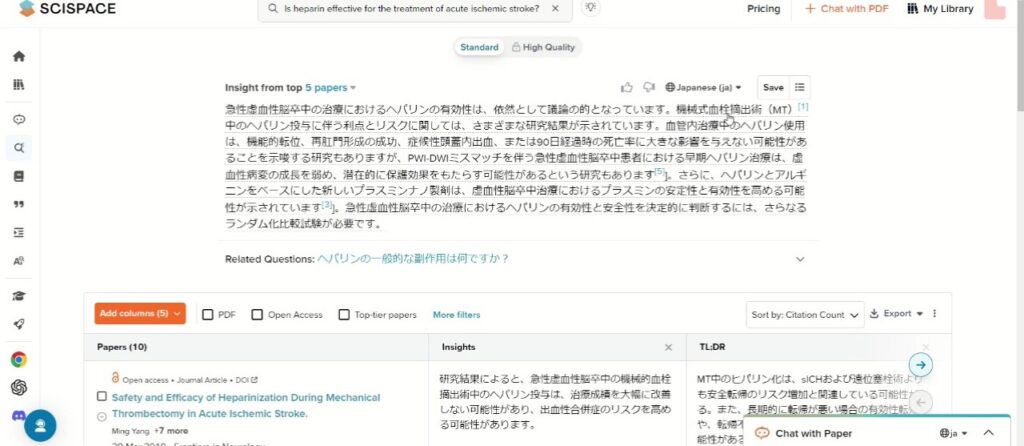
<Scispace(https://typeset.io/)より>
すると上記のように回答が変化しますが、やはり初めに来るのは血管内治療の論文です。なかなかガイドラインで引用されていた論文にはたどり着きません。
引用論文もオープンアクセスのものが目立ちますが、おそらくこれはScispaceがオープンアクセスのデータセットを多く使用しているところによるものなのでしょう。
では続けて「ランダム化試験において」という文言をプロンプトに追加してみましょう。
すると結果は以下のようになりました。
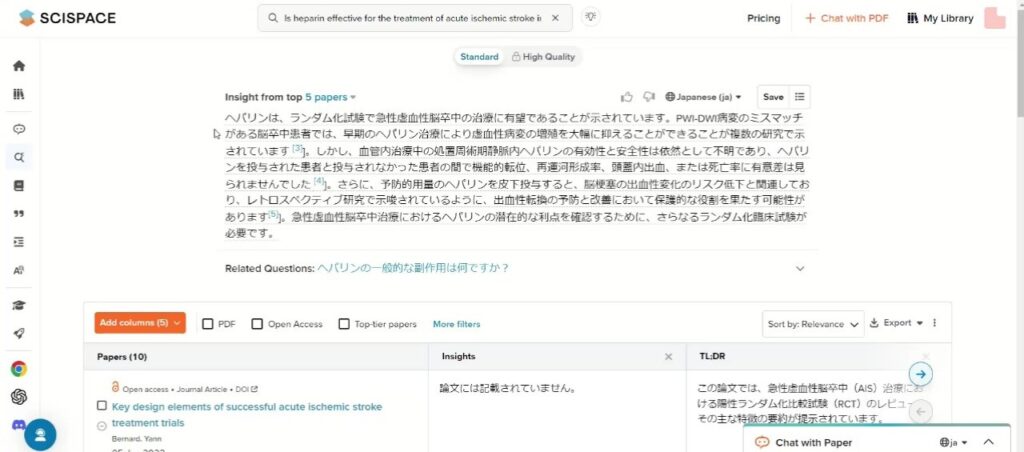
<Scispace(https://typeset.io/)より>
「ランダム化試験で有望」と回答にあるのですが、続く文章に出てくる文献はランダム化試験ではありませんし、他の引用にもそれらしいものはありませんでした。どの文献もランダム化試験の話について触れられてはいますが、実際に行っているわけではありません。
結局ガイドラインの文献にはたどり着かずじまいでした。
ちなみに、この動画と記事を作る際に最初"acute(急性期)"という単語を入れ忘れていたのですが、そうなるとなおさら回答が混乱したものとなっていました。
まず第一にクロピドグレル(抗血小板薬という別の治療薬の一種です)とヘパリンを組み合わせた治療の臨床研究が出てきましたし、上位5つの論文は他にマウスなどヒト以外の研究や、静脈血栓症に関しての研究で副次的に脳梗塞を防ぐ研究結果などどうも本筋とずれてしまっています。
インプットする際の定義と用語の使い方には要注意です。
大規模言語モデルによる文献検索は何が問題か
今回は医学の中でも臨床と直接的な関係が深い質問を使ってみました。大規模言語モデルによるScispaceでの回答の傾向として特に気になった点をまとめてみます。
- 背景情報の判断は難しい
まず今回の質問では「脳梗塞急性期」の一般的な状況として「血管内治療をしていない」状況を想定していました。また、「ヘパリンの有効性」を聞きたいので、他の薬は抜きにして有効性がどうなのかを聞くつもりでした。これらの背景情報はおそらく医師同士であれば何も言わなくてもこの前提に立って話をすることが多いのですが、こうしたことは配慮されませんでした。
前後の文脈よりももっと広い範囲での基本的な背景知識というのはなかなか処理するのが難しいのかもしれません。
逆にこれらについてはインプットする側が知っていないといけないとも言えます。例えば、今回は薬剤の名前を「ヘパリン」と適当に入れましたが、「低分子ヘパリン」なのか「未分画ヘパリン」なのか種類についても言及するのが本来適切です。上述した「脳梗塞急性期」の一般的な状況も、診療に携わった医療従事者なら分かりますが、そうでなければ分かりません。
使う用語の定義や質問内容の前提条件は自動的にAIが意図を汲んでくれない可能性があり、その場合はインプットする側が十分に自覚して細かい指示を出すべき、ということは理解しておいたほうが良さそうです。
つい最近の研究ですが、JAMA Network Openで日本の敗血症ガイドラインに対する臨床的な疑問に対して集めた論文を選別するために、ChatGPTを使った研究がありました3。人が選別した場合と比較しても精度はかなり良かったのですが、Supplementにあるプロンプトをみるとかなり細かく指示が出されています。逆に言うと質問内容をしっかり絞り込む必要があるわけです。普段の会話と同じ調子で質問を出せばどうしてもAIの解釈に幅が出てしまうと思います。
- 回答はデータセットに強く依存する
Scispaceのような言語モデルはデータセットに基づいて回答を導き出します。これらのツールはよくAI(人工知能)と呼ばれますが、人間の持つ知能とはそのデータセットが限定的である点で大きく異なります。特にScispaceは公式の説明によると「2億以上の文献メタデータと5千万以上のオープンアクセスのフルテキストのデータをもとに」アウトプットが行われているようです。
先ほどの質問の例ではオープンアクセスの論文の引用が多くみられました。フルテキストでデータを保持している分、オープンアクセスの方がより合致するテキストが出るのはこのためではないでしょうか。文献メタデータはアブストラクトも含まれると思いますが、それだけではなかなかヒットしないようにも思います。
逆にこの点は自分の持っているpdfファイルをアップロードしたライブラリであればある程度防げるのかもしれません。
- データの価値判断は事前に設定されていないと難しい
得られた参考文献の研究がどの程度確度や妥当性が高いのかは単に文章内容だけによらない価値判断が必要です。マウスなどの動物実験も時折結果に出てきてしまっていましたが、これは単に結果や考察部分に「~という治療が有用であるかもしれない」という示唆が含まれているためそこを拾ってきてしまうからだと思われます。
特に臨床医学において「ランダム化比較試験」は研究の対象者が限られるものの、一般的に結果についての妥当性は高いです。こうした文献をより優先的に引用するには、研究ごとに何らかの価値の重みづけが必要です。
ただ、難しいのは、「質の良いランダム化比較試験」というのをどう考えるかです。ただランダム化比較試験に分類されているものを拾ってこればよい、という単純なものではなく、盲検化がされているか、アウトカムの測定方法は適切か、途中脱落があまりに多すぎないか、など妥当性を考慮する項目は多数あります。ここまでの複雑な価値判断をするのは人間でも難しいですが、AIで行うのも困難なように思います。
例えば、ランダム化比較試験や観察研究のバイアスを評価するためのツールとしてシステマティックレビューを補助するAIツールがありますがこれもまだまだのようです。2022年時点ですが、AIによるシステマティックレビューツールの報告をまとめたJournal of Clinical Epidemiologyのレビューでは各評価の感度や特異度も様々で、安定しているようには見えません4。また、Preprintの査読前論文ですが、ChatGPTでRoB 2.0という代表的なバイアスリスクの評価方法を使えるかどうか見た論文では実際のコクランレビュー(バイアスリスクを丁寧に評価した厳格なレビュー)による結果とChatGPTによる評価はうまく合致しないようです5。
限られた環境であればそれぞれに発展はしていますが、総合的かつ汎用的な文献検索ツールとして正確な妥当性を判断するのはまだまだかなり難しいだろうと言えます。
まとめ
Scispaceのliterature review機能において、臨床的疑問に対する回答を日米ガイドラインと比較してみました。
引用文献はほぼ合致せず、この例においては質問における具体的な背景や、元となるデータセット、妥当性の判断において問題があるように思われました。引用文献の問題はありますが、専門家内でも意見が完全に合致しているような例では、もう少し期待した回答に近いものが得られているようには思います(例えば脳梗塞に対するアスピリン使用など)。また、分野によって期待した回答とのずれには異なる側面があるかもしれませんが、ここで挙げたような根本的な問題はあまり変わらないでしょう。
日進月歩のAIツールですので、今後元となるシステムがうまく調整されれば、こうした問題点も解決できるかもしれません。
今後は他の文献検索ツールについても検証していきたいと思います。
参考文献
- 脳卒中治療ガイドライン2021(改訂2023) https://www.kk-kyowa.co.jp/stroke2021/ ↩︎
- Guidelines for the Early Management of Patients With Acute Ischemic Stroke https://www.ahajournals.org/doi/10.1161/STR.0000000000000211 ↩︎
- Oami, Takehiko, Yohei Okada, and Taka-aki Nakada. “Performance of a Large Language Model in Screening Citations.” JAMA Network Open 7, no. 7 (July 8, 2024): e2420496. https://doi.org/10.1001/jamanetworkopen.2024.20496. ↩︎
- Khalil, Hanan, Daniel Ameen, and Armita Zarnegar. “Tools to Support the Automation of Systematic Reviews: A Scoping Review.” Journal of Clinical Epidemiology 144 (April 2022): 22–42. https://doi.org/10.1016/j.jclinepi.2021.12.005.
↩︎ - Pitre, Tyler, Tanvir Jassal, Jhalok Ronjan Talukdar, Mahnoor Shahab, Michael Ling, and Dena Zeraatkar. “ChatGPT for Assessing Risk of Bias of Randomized Trials Using the RoB 2.0 Tool: A Methods Study,” November 22, 2023. https://doi.org/10.1101/2023.11.19.23298727.
↩︎


コメント