





This time, I'll introduce RAG, an AI terminology that researchers should also know.
- What is RAG?
- Examples of tools using RAG
- Why researchers need it
- How RAG works
I'll provide a comprehensive introduction to these topics, so if you're interested in efficient information gathering using AI, please take a look.
What is RAG
RAG stands for "Retrieval Augmented Generation."
It's a mechanism where large language models incorporate external information to generate more accurate responses. This approach was proposed by Facebook's research team in 2020 and is now utilized in many AI systems.
While ChatGPT, Gemini, and Claude are highly accurate, they sometimes make mistakes due to information gaps in specialized knowledge.

Creating specialized models through extensive training each time is inefficient, but by having excellent general-purpose models reference external information, accurate responses can be obtained while keeping costs down. This is the core concept of RAG.
Examples of RAG Tools
Actually, many of the tools you're using are RAG systems.
The popular Google NotebookLM is a personal RAG that can accurately extract information from PDFs, audio, and text files. It's particularly useful for researchers as it allows verification of cited sections.

From Japan, there's a preprint paper on Arxiv that reports using Google NotebookLM for lung cancer staging. This shows that RAG is indeed useful for applying specialized knowledge.
Also, AI paper search tools are exactly RAG systems where LLMs pull information specifically from paper databases.
Why Researchers Need It
Researchers work to pioneer knowledge that no one else knows. They need to investigate and organize things that general-purpose models don't know.

Moreover, in papers and presentations, accurately grasping the literature that serves as evidence is essential. RAG can clearly identify sources and extract information from large amounts of data, making it extremely useful for researchers.
Let's briefly look at how RAG works.
How RAG Works
Information Retrieval
First is information extraction. One commonly used method is converting text into vectors (arrays of numbers) to enable natural language search.
The concept looks like this:
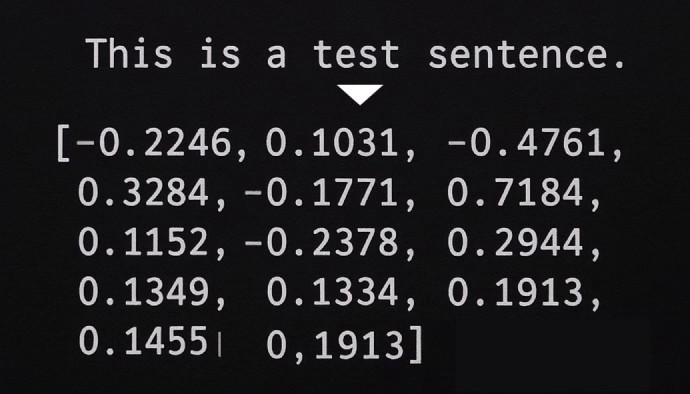
Similar content is placed at close distances, while different content is placed at distant locations. For example, if we embed words using 2D vectors, it would look like this image. Not only words but also sentence units can be embedded with vectors in this way, allowing us to measure differences and similarities between sentences.
▼ Mario family characters are close together, while Pokémon are a bit further away
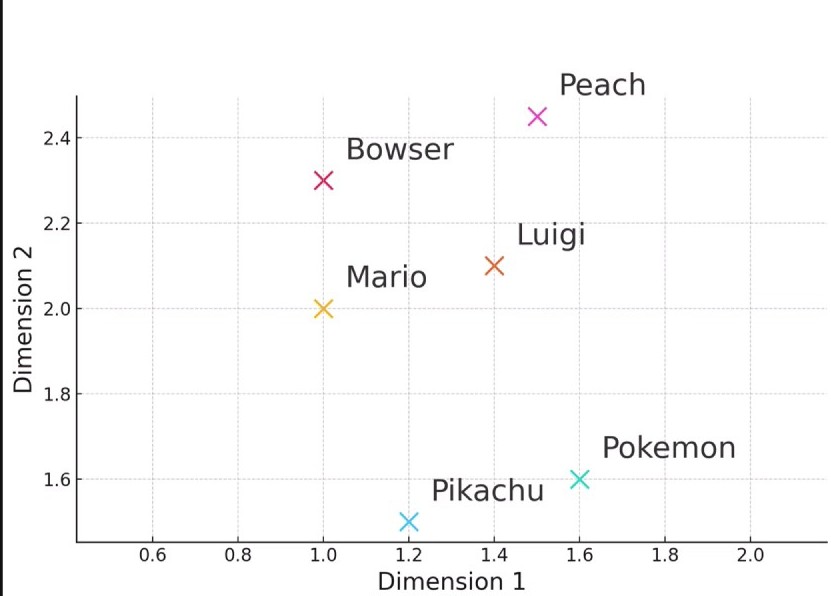
I simplified this to 2D for clarity, but in reality, even ultra-lightweight models process in complex spaces of 300+ dimensions. This processing requires significant machine power and capacity, so it's not easily feasible on regular PCs.
However, with large language models like ChatGPT, you can use APIs over the internet to substitute this processing, so if you're willing to pay, you can perform embeddings on your own text even with a laptop.
In this work, appropriate chunking (dividing text into appropriate sections) is crucial. For difficult-to-process files like PDFs, it's important to divide them by meaningful paragraph units rather than simply by character count or line numbers when embedding. If meaning is cut off midway, search accuracy significantly decreases.
Finally, using these vectors to calculate corresponding answers to question sentences allows finding natural responses.
There are also methods where LLMs generate keywords derived from search terms and investigate each one. For example, if you search for "Sports," it automatically searches for Basketball, Baseball, Soccer, etc. While you can't understand fine context, you can perform broad searches.
Recently, "hybrid retriever" methods that combine vector search and keyword search have gained attention and are actually implemented in many RAG systems when you look at the code. This enables leveraging both semantic similarity and exact keyword matching, allowing for more accurate information extraction.
Incidentally, I suspect that when Google NotebookLM and similar tools highlight text at the sentence level during citation, this corresponds to the embedding units (chunks). With properly chunked documents, you can show citation sources in meaningful units.
Furthermore, after this, it's important to rank and deliver the information retrieved through search. The weighting of different information varies by tool, so results can change significantly based on these priorities.
Generation
Then comes the generation stage.
The extracted information is input into the LLM, which generates a comprehensive response. Results vary greatly depending on how much the LLM's internal knowledge is blended, the prompt content, and input information volume adjustment.
For example, comparing Scispace and ChatGPT, Scispace primarily uses knowledge written in papers, while ChatGPT uses a higher proportion of internal knowledge.

(Left: Scispace, Right: ChatGPT)
If you want to prioritize information from papers, Scispace is better, while ChatGPT is preferable for more general knowledge.
The content and volume of output also change based on input information volume. Among the AI paper search tools I recently introduced, AnswerThis AI has very high input volume and correspondingly high response volume.
I think results vary significantly depending on the internal model used in the generation process.
However, for researchers writing papers, models that prioritize accuracy are preferable—models that clearly state when something isn't written rather than making things up. In this regard, NotebookLM is indeed excellent.
I've also summarized what should be prioritized and how in previous articles, so please check those out as well.
Summary
- RAG is a mechanism that achieves high-precision output by incorporating external information into large language models
- It's an optimal tool for researchers dealing with specialized knowledge
- Results vary greatly in each process of preprocessing, extraction, prioritization, and generation, so understanding the processing content is important when using it
Incidentally, I've been obsessed with the integration of Claude and Obsidian lately, processing paper and memo information with Claude. It's incredibly useful, so I'll introduce it again next time.


コメント