





今回も引き続きAIを使用した文献検索機能のツールelicitを紹介してみたいと思います。
学術文献に特化しており、表も見やすく使いやすいのですが、初回の試用以外は有料なのが難点となっています。
動画による解説も以下にありますのでよければご覧ください。
Elicitとは?
Elicitは学術的な文献に絞って検索を行うAIツールです。アメリカの非営利企業であるOughtによって2021年に作られました。機械学習により論理的思考を高めることを目標としており、Elicitはその一環として生み出されたものです1。
また、今後の計画についても公式サイトに書いてあり、特色としてアウトカムベースではなくプロセスを重視してることなどが語られています。これからの方向性についてもうかがい知ることができます(とはいえ2022年の記載のようですが)2。
Elicitは入力されたプロンプトを元に、キーワードを生成し、それに対する回答を引用文献付きで記載します。ぱっと見は以前紹介したScispaceのLiterature Review機能と似ているかもしれません。

ですが、こちらの方が論文の質や種類によるフィルタリングやソースの追加・削除といった機能には優れており、データソースも異なります。
Elicitのデータソースは公式サイトで明言されており、主にSemantic scholarです3。
Semantic scholarは機械学習を活かした文献検索ツールで2024年現在で2億以上の文献がストックされています。文献情報としては幅広く集められていますので、概ね自分の読みたいような論文は含まれていることが多いです。
逆に学術文献限られているため、成書などは含まれない点には注意が必要です。
料金
さて、個々の機能の説明に関連するので、先に料金体系について述べておきたいと思います。
elicitは基本的に有料です。
お金を払って毎月もらえるクレジットを使って検索や要約を行います。 初回お試しのBasicプランであれば無料で5000クレジット手に入りますが、それ以降はお金がかかります。
Elicit plusのプランでは年間契約なら月$10、月々の契約なら月$12となっています。 お金を払うと毎月12000クレジットが手に入ります。
このクレジットがどのくらい役に立つかですが、公式ページに概ねどの程度の機能でどの程度クレジットを消費するかが書いてあります4。
機能の説明はそれぞれ後述しますが、大体以下のような感じです。
- 論文を見つける:50〜120クレジット
- PDFからデータを抽出:アップロードする論文の数、長さ、抽出するデータに依存しそれぞれ
- 要約リスト:500〜2500クレジット
- 表への列の追加:1セルあたり30〜100クレジット
- 高精度モードでの表への列の追加:1セルあたり200〜500クレジット
要約した表に列を追加したりすると結構かかりますし、これが10~20くらいの論文を含む表ですと一気に1000近く消費します。
正直何も考えずに使うと12000クレジットもすぐなくなるのではないでしょうか。 追加購入もできるようですが、さらに費用がかさむとなると中々高い印象はあります。
基本的な機能と使い方
主な機能は以下の3つです。
- Find papers(文献検索)
- Extract data from PDFs(アップしたPDFからの抽出)
- List of Concepts(専門的な概念のリストアップ)
それぞれ見ていきます。
Find papers(文献検索)
まずは中央の"Find Papers"のフォームから文献検索ができます。 上述した通りElicitの回答は構造がscispaceに似ています。
まず中央のフォームに質問をインプットします。
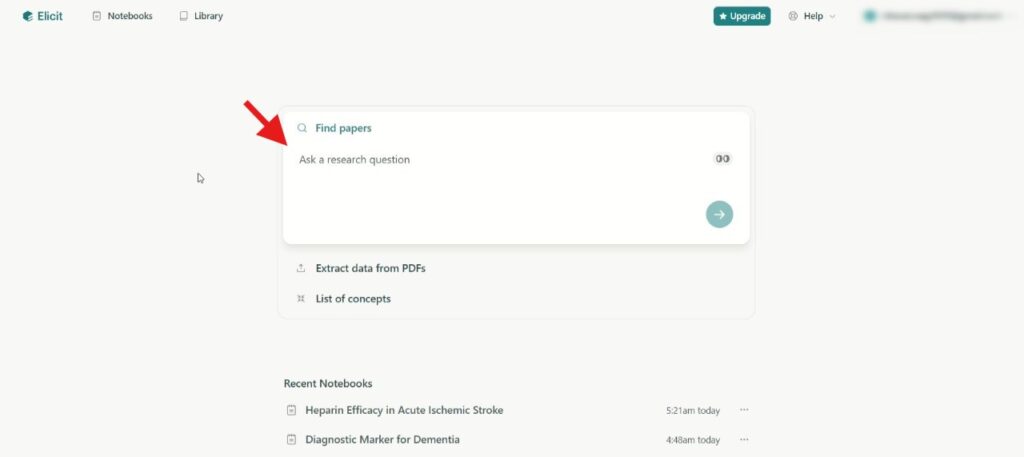
すると質問が簡易的なキーワードとして整理され、回答とその引用文献が並びます。

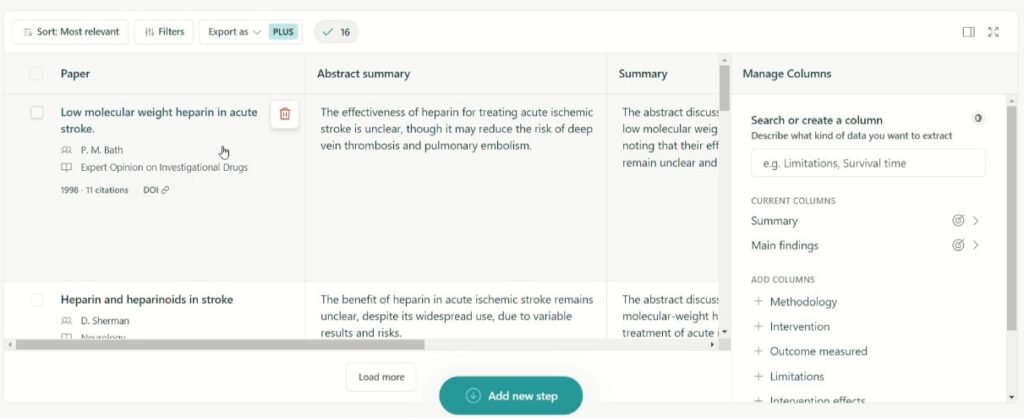
それぞれの論文をクリックするとアブストラクトとSemantic scholarへのリンク、DOIが表示されます。
また、pdfファイルが入手可能な論文についてはその場で全文を読むことができます。
引用文献の追加・削除もその場でできるので、さっと見て関係あるかどうかを判断し、この画面に残しておくかどうか取捨選択できるのは良い点ですね。また、それなりに古い論文も含め、オープンアクセスかどうかを問わず、幅広く抽出されていることが分かります。
文献のフィルタリング機能と要約
表示した引用文献について引用回数や新しい順・古い順などのソート機能はもちろんのこと、フィルタリング機能も充実しており、年代やジャーナルのクオリティ、研究の種類(メタ解析、システマティックレビュー、ランダム化比較試験など)によって選別することができます。
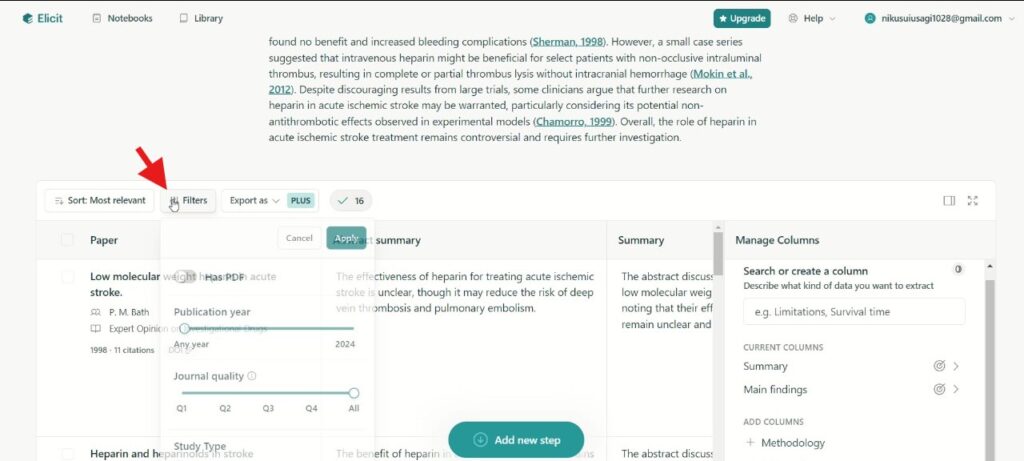
ジャーナルのクオリティはSCImago journal rankという格付けによって分類されます。このランク付けでは過去3年間の引用回数などを用いていますが、単純な引用回数だけではなく、引用しているジャーナルのランクも考慮していることが特徴的です5。このフィルタでは調べたい分野におけるジャーナルランクがQ1-4のどの四分位範囲に入るかで選別することができます。
四分位範囲について分からない人は手前みそですが、運営中の医療統計YouTubeも観ていただけますと幸いです。
さらに引用論文は表の形で要約されて提示されます。なお、要約は単純に論文の主張を要約したものではなく、「検索したキーワードに関する内容の要約」となっていますので、論文そのものの主な内容とは異なる点に注意が必要です。
Elicitではさらに、この引用論文の要約したい内容を追加したり、特定の内容を抽出したりすることもできます。例えば被験者やどこで研究が行われたか、など知りたい情報に応じて内容を抽出+要約することが可能です。
この辺りの細かい機能は公式のYouTubeチャンネルの解説もかなり充実しているように思います。
サイトによるYouTube公式チャンネル→ https://youtu.be/6C6wJfvvPlw
過去の検索内容の確認
以前に行った検索内容の確認はNotebookページからみることができます。
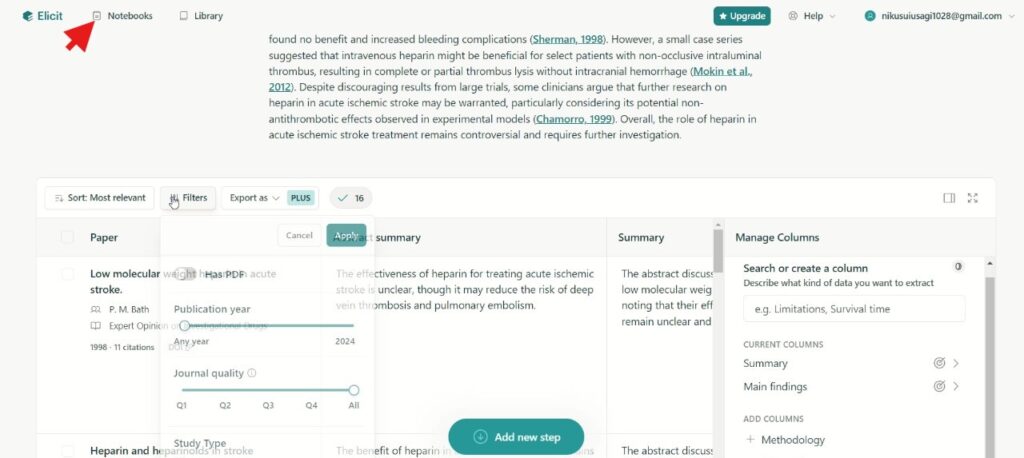
こちらで過去の検索内容がみられるほか、クリックすると引用文献と回答も確認できます。
ここで各項目を押して、add new stepを押すと新たに追加したキーワードも並べてみることができます。
Extract data from PDFs(アップした論文からの抽出)
文献検索以外の機能として手持ちのPDFファイルをインポートし、文献検索の際に出てきたような表形式でのまとめをしてくれます。ホーム画面の"Extract data from PDFs"を選びます。
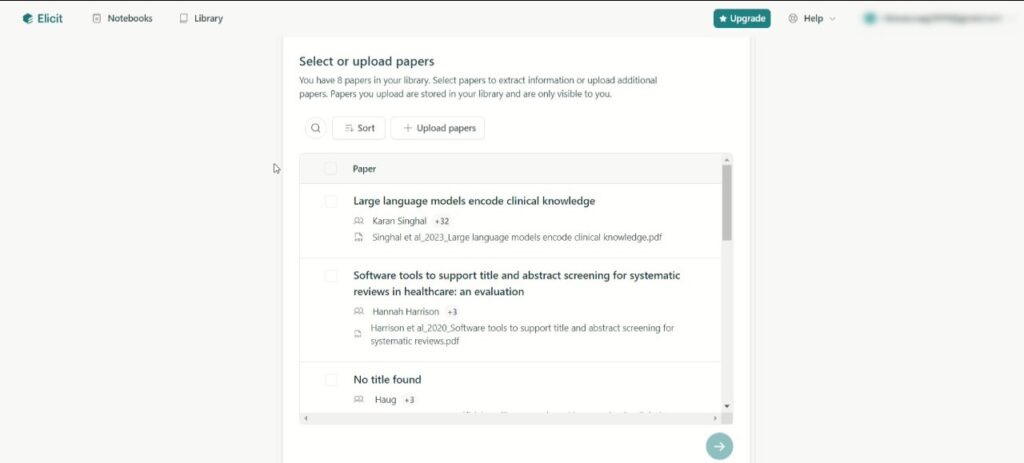
ここでまとめたいPDFを選択し、表を作ることができます。最初に一覧を作る際にはクレジット消費はありませんが、表に項目を追加するにはそのたびにクレジットの消費が必要なので注意してください。
さらにこの表の画面から個々のPDFを選択して、要約をしたり、別の表を作ったり、(β版ですが)PDFの内容について質問することもできます。
なお、要約の言語は英語しかありません。
表を作るためのPDFはLibraryというストック場所から選ぶこともできます。
Libraryのページでは手持ちのPDFファイルの論文やZoteroからの取り込みができ、タグをつけることで分類して整理することもできます。
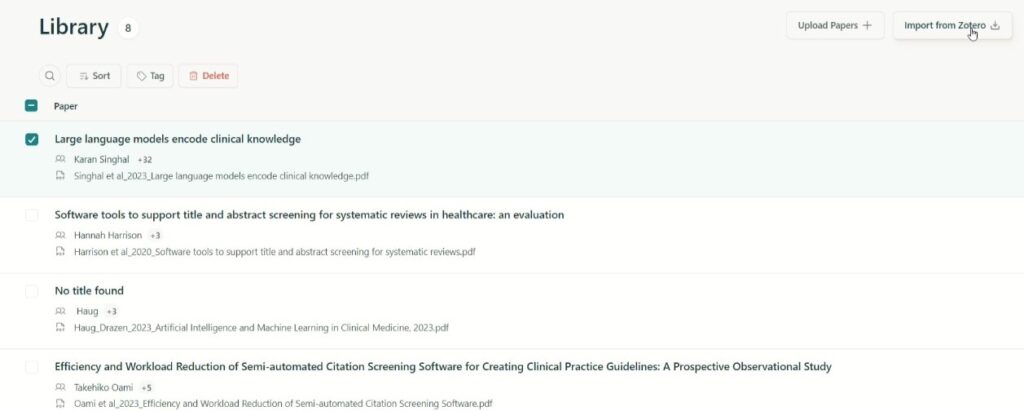
Zoteroからの取り込みができるということで、Zoteroユーザーで良かった、、、と思ったのですが
ここで注意が必要なのはZoteroの公式ストレージかWebDAVを使用していないと、どうやら同期ができないようです6。
PDFファイルの元データにアクセスできないといけないからだろうと思います。
Zotfileを使ってクラウドにあげているユーザーにとってはこの点はイマイチと言わざるを得ません。。。
ちなみに紛らわしいのですが、Libraryページからはこの表を作ることはできず、ただPDFを眺めて整理することしかできません。
List of concpets(専門的な概念のリストアップ)
もう一つは何らかのトピックについて横断的に文献を検索し、関連する概念をリストアップしてくれる機能です。
公式ページの例では"effects of invasive species(外来種の影響)"が挙げられています。
今回Diagnostic marker for dementia(認知症の診断マーカー)という単語で検索をしてみました。結果は以下のようになっています。今回の例ではNeurofilament light chainといった生体内のバイオマーカーからMoCAという定番な認知機能スケール(質問の検査で行う)ものまで幅広く検出されました。
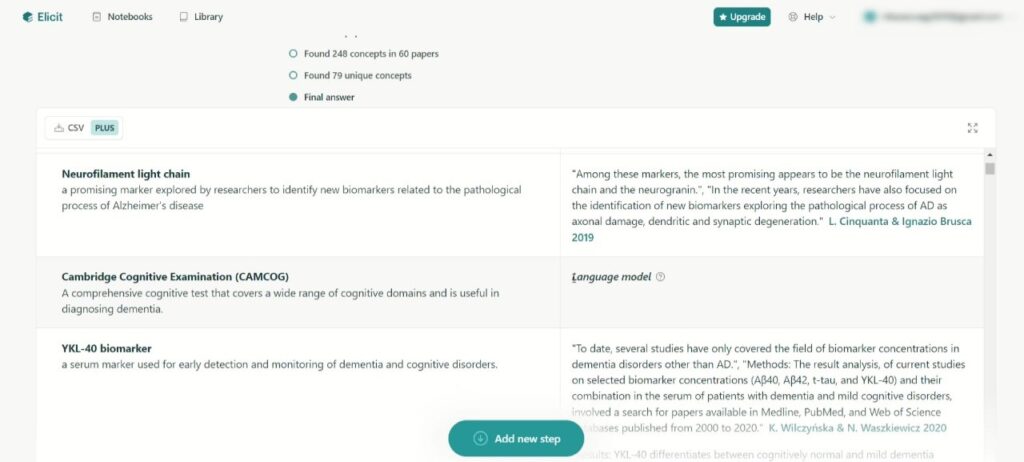
検索後のツールの動きですが、まず関連する論文を検索し、そこから概念をみつけ、さらに絞り込みます。その後どういう処理かは分かりませんが、最終的に絞られたコンセプトとそのソースが表にして提示されます。ソースはそれぞれ引用部分の文章もみることができ、どのようにその用語が使われているのかまで分かります。
また、用語の一部では、ソースなしで大規模言語モデルで導き出されたものもあり、そこに関しては自身でのダブルチェックが必要そうです。
まとめると特定のトピックに関する専門的な概念を引用付きで網羅的にまとめてくれる機能というところでしょうか。自分がこれから調べたいトピックについて知識を広げるためには非常に役立ちそうな機能です。
難点はクレジット消費が大きいことで、今回の検索では1266クレジット消費しました。月12000クレジットと考えると、1カ月に10回は使えないので、使いどころが悩ましくなってしまいますね。
臨床医学に対する実際の例
さて、これまで他のツールでもその精度を確認するために自分の詳しい分野の質問をやってきましたが、同じ質問をここでも投げてみようと思います。
質問はこちらです。”Is heparin effective for the treatment of acute ischemic stroke?”
文章での質問でしたが、まず次のようなキーワードに変換されていました。
Heparin Efficacy in Acute Ischemic Stroke
その検索結果から概ね次のような回答が得られました。

- 大規模試験では有効性はなく、出血のリスク増加が指摘されている(根拠はreview)
- ケースシリーズでは有効性のある報告もある(根拠はcase series)
- 今後もさらなる研究が必要である(根拠はreview)
説明事項としては概ね間違っていないと思うのですが、引用しているレビューがいずれも1990年代終わりのものでなぜだか古いんですね。もしかしたら引用数などの影響もあるのかもしれません。ただ、本来入ってほしいのはガイドラインで引用されているようなメタ解析の論文でしたが、その辺りは含まれていませんでした。
検索後のフィルタ機能は充実していますのでこの辺りを改善できるようにフィルタを設定してみます。
2000年以後の出版に限定してみました。
すると、概ね回答の方向性は変わりませんでしたが引用が2006年のレビューに変わりました。

回答に対する他の引用もcase seriesとreviewが主体で、なかなか出てほしいメタ解析はありません。レビューから引用してきているので内容として大まかな間違いはないのかもしれませんが、イマイチきっちりした根拠までは導き出せませんでした。
この点ではPerplexityは幅広くレビューやインターネットの情報を主体に検索するためもう少し視点の広いバランスの良い回答でしたが、学術文献にデータベースが限られていることから、ごくわずかなレビューに偏ってしまっている印象があります。その割には一次情報にはたどり着けていない点が残念です。
他のツールにおける文献検索機能の検討については以下のページもご参考ください。


まとめ
Elicitは学術文献に限定してAIを用いた検索ができ、フィルタリングや要約機能が充実したツールです。また、特定のトピックから専門的な概念を掘り下げる機能は特に独自性があり、0から深掘りしていくためには非常に役立つ機能だと思いました。
しかしながら何を使うにもクレジットが必要で、探索的な文献調査がしにくいという欠点があります。文献を検索する段階では目的が十分定まっていないことが多いと思いますので、お金による使用の制限がかかるのは相性が悪いです。
フィルタリング性能や対象となるデータベースと独自機能においてScispaceとは異なる良い点があると思いましたが、この欠点ゆえに個人的にはあまり使う気持ちになれませんでした。
検索のみであればそこまでクレジットも消費しないので、検索を主体に使っていくならありかなと思います。
次回は引き続き文献検索ツールであるConsensusをみていきたいと思います。


コメント