





I often hear people say, "There are too many tools for literature search and information management with AI—I don't know which ones to use or how to use them." Indeed, research support tools including generative AI are rapidly proliferating, and trying them all is simply unrealistic.
In this article, rather than memorizing the features of individual tools, I'll introduce a method for organizing them by understanding tools as "abstract structures." By viewing mechanisms from a higher-level perspective, you won't be confused no matter how many new services emerge in the future.
The "Too Many AI Tools" Problem
Not limited to literature search tools, there's an overwhelming number of AI models, especially LLM-based ones, proliferating rapidly. The proliferation of tools incorporating generative AI likely stems from factors such as:
- LLMs are currently positioned at the center of information processing
- LLMs can handle all types of data formats
- A market structure where "adding AI equals adding value"
Given that many AI tools are still in development, this situation will likely continue for some time. Therefore, it's important to have classification axes rather than memorizing tool names and features.
Understanding Tools Through Structure
To organize tools, focus on just these two points:
Input (What sources of information are used?)
Output (In what form are results returned?)
Example: General-Purpose LLMs (Large Language Models)
Let's consider general-purpose LLMs like ChatGPT.
Input Range:
- User questions
- Training data (massive amounts of text)
- Web search and paper information as needed
Output Characteristics:
- Text
- Flexible formats like tables, summaries, explanations
In other words, the structure has broad input and high freedom in output.
For example, if you ask "What is ChatGPT's training data made of?", it can summarize the information in a table as shown below.

▲Example: ChatGPT's training data sources summarized in table format
Example: Paper Search-Specialized Tools
Now let's consider paper search-specialized AI tools like Consensus and Scispace as a comparison.
Input Range:
- Paper databases
- Abstracts
Output Characteristics:
- Text responses
- Paper metadata (citation counts, study design, etc.)
The key feature is that while input is limited, output is optimized for researchers. In addition to text responses, you get tables and paper information (citation counts, journals, study design, etc.) simultaneously.
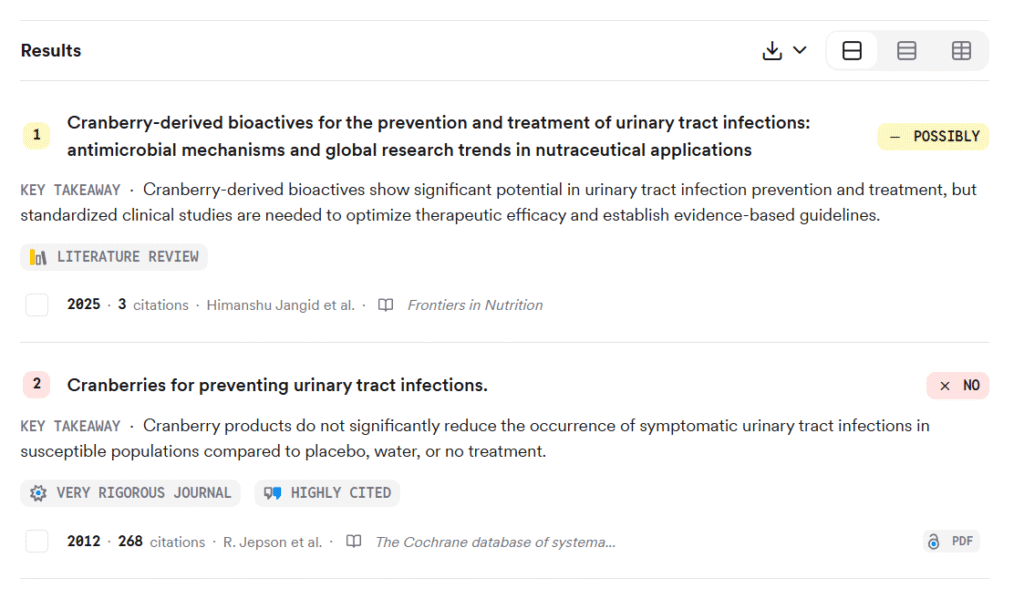
▲Example: Consensus clearly displays study design and citation frequency with icons
The output information is easy to view, and you can get an overview of individual papers. Depending on the tool, you can also save to a library or easily share with reference management software like Zotero.
In reality, the papers that come up in queries don't seem to differ much between ChatGPT and these specialized tools, but I believe the advantage of these paper search-specific tools is that the output format is tuned to be user-friendly for researchers.
Conversely, if you want information from the web beyond papers, or if you want flexibility in output format, general-purpose LLMs are more convenient.
Comparing them this way, general-purpose LLMs basically have broader coverage in the input section, so you might argue that general-purpose LLMs alone are sufficient. This is largely due to the expanded functionality of general-purpose LLMs.
If that's the case, there's no need to force yourself to use paper search-specialized tools unless you find strong appeal in their output.
By deciding which tools to use based on what you want as input and what you want to get as output, you should naturally see which tools you want to use.
Summarizing the input and output of other tools similarly yields the following table:
| Example | Input | Output |
|---|---|---|
| ChatGPT | Public paper data, web, training data | Responses, etc. |
| Consensus | Public paper data | Responses + tables + lists |
| NotebookLM | User-selected data | Responses, etc. |
| OpenEvidence | High-quality papers, guidelines | Responses |
Google NotebookLM allows you to narrow down data to selected papers, while tools like OpenEvidence output responses limited to curated papers such as reviews from high-impact journals and guidelines. I've introduced these in the following articles:


These tools have high uniqueness in both input and output, making them difficult to replace with general-purpose LLMs. Therefore, they have relatively high value for use cases separate from general-purpose LLMs.
By focusing on how input and output differ from existing tools, you won't need to try or jump on every new tool that comes along.
Examples of Tool Differentiation
So how do you actually differentiate between these when searching for and organizing papers?
One example is to think about differentiation in terms of how broadly you want to expand the scope of what you're investigating when researching papers.
Considering the input range, general-purpose LLMs have the broadest scope from websites to papers, while Google NotebookLM only uses papers you upload, making it the narrowest. Looking again at the tools mentioned earlier, they can be summarized as shown below:
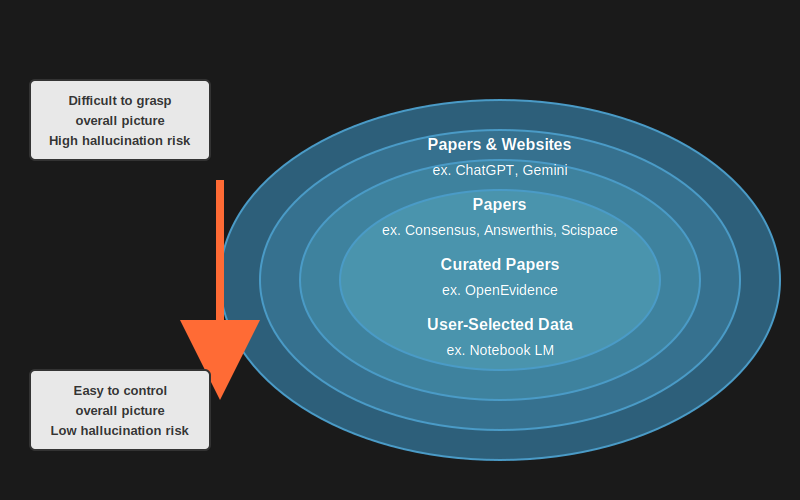
For example, when investigating prior research, don't you want to search as broadly as possible at first? It's quite difficult to narrow down papers from the start, and if you miss information, it can be irreversible later. It would be devastating if the research you're trying to do has already been done.
Therefore, when searching initially, search from as broad a range of sources as possible. That is, use general-purpose LLMs or paper search-specific tools to investigate papers.
As an exception, tools like OpenEvidence (limited to medical fields) can also access information from papers behind paywalls (paid papers), so if such tools emerge in your field in the future, it would be good to use them in combination. Information that can be searched with general-purpose LLMs inevitably tends to be biased toward open access.
When the scope is broad, it may be unclear where and how the LLM is obtaining information, and there's a risk of hallucinations, but accepting this as just the initial information gathering stage, collect information broadly.
Next, when you've grasped an overview of prior research, LLMs with narrowed information sources like NotebookLM become useful. This is because you can directly reference the papers that the LLM's responses cite, reducing the risk of hallucinations and ensuring accuracy through your own verification. When planning experiments or narrowing down research objectives, accuracy is important, so these tools are useful at such stages.
Understanding which tool to use while imagining the input and output is key to differentiating between tools.
Summary
- Tools can be organized by input and output
- Broader input is suitable for information gathering but requires precision management
- Narrower input is suitable for verification and deep dives
- No need to memorize tool names—understanding abstract structure is essential
With this perspective, you won't be overwhelmed by literature search in the generative AI era. Please try reviewing the tools you're currently using from this perspective.


コメント