





言語学習において、フレーズを覚えたり、ストックして復習するのは一つの手段だと思います。ただ、フレーズを貯めても復習がうまく続かなかったり、繰り返す暗記に疲れてしまったりすることはよくあります。Ankiなどのツールは有名ですが、個人的には何度もトライしたものの、飽き飽きしてしまって1カ月以上続きません、、、。
Duolingoなどの学習ツールはそうした繰り返しの学習を楽しくしてくれるお供ですが、自分が学習したい内容やフレーズにピッタリ当てはめることは難しいところがあります。
そこで本記事では、Claude MCPとCSV/SQLで作ったフレーズのデータベースを組み合わせることで、自分が学んだ第二言語のフレーズや単語を外部化し、それをより自然な形で活用できる実践例と方法を紹介します。
Claude MCPとは?
Claude MCP(Model Context Protocol)は、Anthropic社が開発したClaude AIモデルと外部システムを連携させるためのプロトコルです。よくUSB-Cに例えられますが、MCPを使用することで、Claudeは従来の内部知識によるチャット機能を超えて、データベースやファイルシステム等の外部リソースと直接やり取りできるようになります。今やClaude だけでなく、OpenAIやGeminiなど他のLLMでも使われるようになっており、今後も拡張性が期待されるプロトコルと言えます。
MCPの主な特徴:
- 拡張性: 様々な外部システムとの連携が可能
- リアルタイム処理: データベースの読み書きをリアルタイムで実行
- カスタマイズ性: 個人のニーズに合わせた機能実装が可能
- セキュリティ: 適切な制限をかけることでローカル環境でも安全に使用
今回の言語学習法ではMCPによって学習者の進度データや語彙データベースと連携し、パーソナライズされた学習を進めることができます。
使い方は書き出すとキリがなかったりするので末尾の参考リンクからClaude公式のガイドをご参照ください。
SQL・CSVデータベース どちらでも使える!
MCPと一言で言っても様々な種類があります。
どこにあるどのようなファイルを対照とするか、またどんな指示を可能とするかはそれぞれのMCPによって異なります。
多くのMCPはGithub上に作られたものがアップされていますが、ローカルのファイルにアクセスすることを踏まえると、ソースコードをきちんと読んでセキュリティ上のリスクがないかを確認するのが無難です。もしくは公式のものや多くの人の目に触れているものを選ぶ方が良いでしょう。
今回は言語のデータベースをCSVやSQLで作る場合に役立つMCPを紹介してみます。
なお、リンクはページ末尾にまとめてあります。
Sever Postgres (SQL用)
- 用途: 構造化された語彙・フレーズデータベースの管理
- 利点: 複雑なクエリによる柔軟なデータ抽出が可能
- 適用例: 学習履歴の追跡、進度管理、関連フレーズの検索
npx -y @modelcontextprotocol/server-postgres postgresql://yourusername:yourpassword@localhost:5432/yourdbname
File System MCP (CSV用)
- 用途: 一般的なローカルファイルの管理と操作
- 利点: 音声ファイルや画像など多様なメディアとの連携
- 適用例: 学習教材の整理など
npx -y @modelcontextprotocol/server-postgres postgresql://postgres:mysecretpassword@localhost:5432/mcpdb
これらのMCPを使うことで、下記の実践例のような言語学習管理システムを構築できます。
server postgresの場合、Claude側での設定用のJSONファイルには以下の様に書き込みます。
"postgres":{
"command": "npx",
"args": [ "-y", "@modelcontextprotocol/server-postgres", "postgresql://yourusersname:yourpassword@localhost:5432/dbname"
]
},
your...やdbnameは適宜自分のものに当てはまるように書き換えてください。
ちなみに複数のSQLデータベースがある場合はこのサーバーだと対応できないのでmulti-database serverがおすすめです。ただ、dockerが必要でさらに技術レベルを要します。こちらも末尾にリンクを載せておきます。
また、filesystem MCPの場合は以下の様になっています。
"file-system": {
"command": "npx",
"args": [
"-y",
"@modelcontextprotocol/server-filesystem",
"<使いたいCSVファイルの入っているフォルダの絶対パス>"
]
}
SQLとは?
あまりなじみがない人も多いと思いますので、SQL(Structured Query Language)についても簡単に触れておきます。SQLはデータベースを操作するための標準的な言語です。言語学習においてSQLを活用することで、膨大な学習データであってもCSVよりも効率的に管理・分析できます。
SQL活用のメリット
柔軟な検索・抽出 「過去1週間で学習したフレーズ」「正答率が低い項目」など、複雑な条件での検索が簡単に可能です。
進度の可視化 学習データの統計分析もしやすいです。
重複の防止 例えば単語や例文が重複した場合にはエラーが出たり、空欄の項目を防止するなど、CSVよりもデータベースの均質化に優れています。
GUIでの入力はCSVよりやや面倒ではありますが、CLIに慣れていればこちらの方が便利で使いやすいです。
下記の実践例はCSVとSQLどちらでも基本的に同じことができます。SQLの方が複雑な検索や統計に向いていますが、CSVの方が手軽で直感的に編集できます。どちらを選ぶかは個人の好みや技術レベルで決めて問題ありません。
CSV・SQLデータベース vs ChatGPTファイルアップロード
ChatGPTやClaude(Web版)でもファイルをアップロードして同様の学習支援を受けることは可能です。しかし以下のような欠点があります:
ファイルアップロードの課題:
- 毎回ファイルをアップロードする必要がある
- セッションが終わると再度アップロードが必要
- ファイルの更新時は再アップロードが必須
- 複数ファイルの管理が煩雑
MCP連携の利点:
- リアルタイムでデータベースが更新される
- セッション間でデータが永続化される
- データの追加・修正が即座に反映
- 複雑な検索クエリが自在に実行可能
つまり、一度設定すればスムーズに継続学習ができるのがMCP最大の魅力です。
言語学習における最大の敵は「めんどうくささ」に尽きると思います。それが楽にできるというのは一番重要な点です。
基本的なテーブル設計例
例えば以下の様な形で、カテゴリや覚えたいフレーズ、作成日、復習したときに正解できたかどうかなどのデータを格納できます。
-- フレーズテーブル
CREATE TABLE phrases (
id INTEGER PRIMARY KEY,
original_text TEXT,
translation TEXT,
category TEXT,
difficulty_level INTEGER,
created_date DATE
);
-- 学習履歴テーブル
CREATE TABLE learning_history (
id INTEGER PRIMARY KEY,
phrase_id INTEGER,
practice_date DATE,
correct_count INTEGER,
total_attempts INTEGER,
FOREIGN KEY (phrase_id) REFERENCES phrases(id)
);
では続いて、実際自分がやっているような具体的な使用例を見てみます。
実践例1:使いたいフレーズの再確認
LLMを使わない場合、フレーズを貯めておいてもきちんと分類をして覚えておかないと、どんなフレーズがメモしてあったか探すのは大変でした。
しかし、LLMがあれば曖昧な質問でも的確にフレーズを抽出してくれます。
例えば「研究発表でグラフの数値の上下について説明に使えるフレーズを抽出して」と言えば:

こんな感じで瞬時に関連フレーズを抽出してくれます。
実際に使う場面になったときに、改めてフレーズを見直したいときには非常に便利です。LLMならではの柔軟な対応ができるのが利点ですね。
ちなみに統計的な解析をしてどんなフレーズが多いかと言ったことも可視化できます。
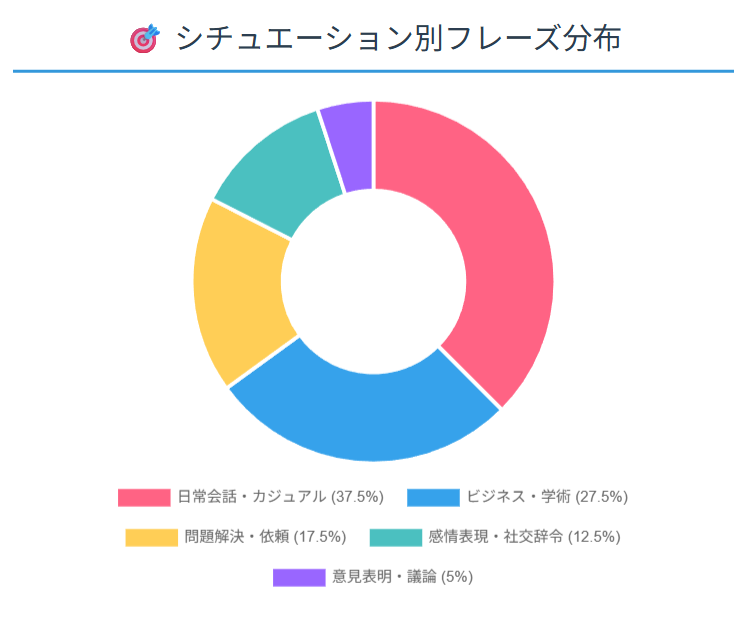
実践例2:直近のフレーズから問題を出させる
覚えたフレーズは定期的に復習することが重要です。MCPを活用すれば自然言語で質問するだけで簡単に復習ができます。翻訳、穴埋め、会話文選択などがよくありますね。

フレーズを単純暗記するだけでなく、思い起こす刺激を与えることで、より実用的な知識を身に着けます。
ClaudeのようなLLMと連携するメリットは、例えば「直近間違えた内容に限定したり」「似た内容の別のフレーズの問題を出してもらう」などが自由自在です。
実践例3:データベースのフレーズを使った会話練習
実際の会話で使えるスキルを身につけるには、覚えたフレーズを実践的な文脈で練習することが不可欠です。
会話練習システムの特徴
シチュエーション別練習
データベースのカテゴリ情報を活用し、「レストランでの注文」「道案内」「ビジネスメールの作成」「研究発表」「研究でのディスカッション」などのシチュエーション別練習を提供します。
例えば以下のようなプロンプトを入力します:

するとデータベースにあるフレーズを使って問題を作ってくれます。

段階的難易度調整
学習者のレベルに応じて、使用するフレーズの複雑さを自動調整します。
リアルタイムフィードバック
Claudeが会話の自然さや文法の正確性をリアルタイムで評価し、改善点を提案します。
研究の内容に限って行うこともできます:

実践例4:既存フレーズからの類似フレーズ拡張
語彙力を効率的に増やすには、既存の知識を基盤として関連するフレーズを追加するとより簡単に知識が広がります。MCPとデータベースを活用した類似フレーズ拡張の方法を紹介します。
類似フレーズ拡張の例
意味的類似性分析
Claudeが既存フレーズの意味を分析し、同じ文脈で使用可能な類似表現を生成します。
文法パターン展開
基本的な文法構造から、より複雑な表現への段階的な拡張を提案します。
レベル適応拡張
学習者のレベルに応じて、適切な難易度の類似フレーズを自動生成します。
例えば実践例1でまとめたようなフレーズを以下のプロンプトでさらに広げることができます。

さらにこれらの単語やフレーズから例文を作ってデータベースに追加するといいですね。
実践例5(SQL向け):データベースのタグ付け提案
効率的な復習のためには、フレーズの分類と整理が重要です。ただ自分で一つ一つやっていくのは結構面倒ですね。そこでMCPを活用した自動的なタグ付けシステムを紹介します。
自動タグ付けの仕組み
意味解析
Claudeがフレーズの意味を解析し、適切なカテゴリを自動提案します。
使用頻度分析
学習履歴から使用頻度を分析し、重要度に応じたタグを付与します。
関連性検出
既存のフレーズとの関連性を分析し、グループ化を提案します。
Claudeは各フレーズを分析し、以下のようなタグを提案します:
- 機能別: greeting(挨拶)、request(依頼)、opinion(意見)
- 場面別: business(ビジネス)、casual(カジュアル)、formal(フォーマル)
- レベル別: beginner(初級)、intermediate(中級)、advanced(上級)
この自動タグ付けにより、体系的にフレーズを管理し、効率的な復習計画を立てることができます。
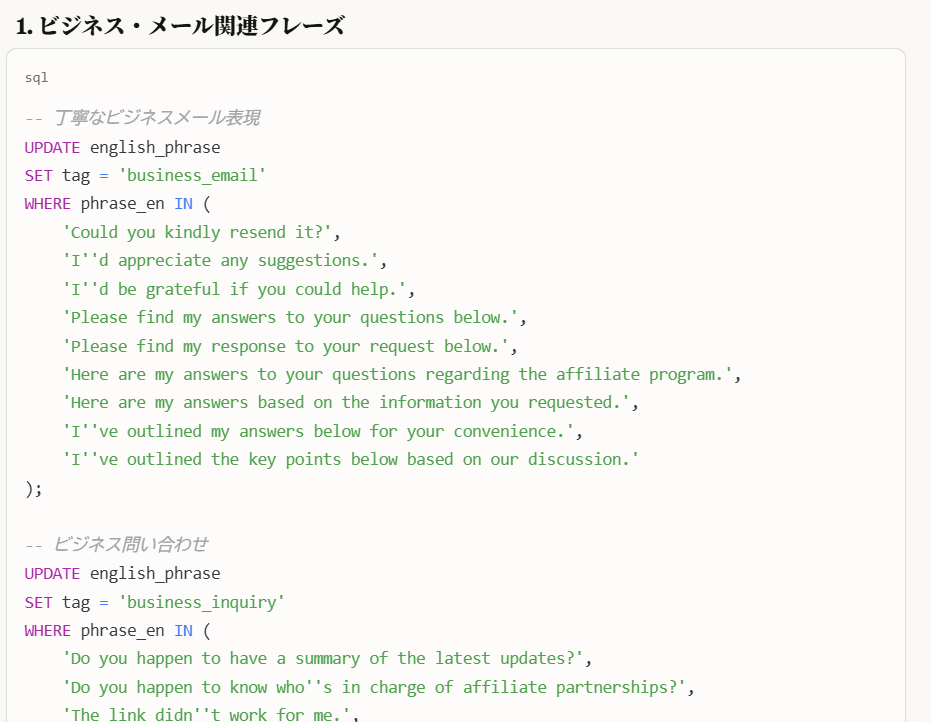
今回紹介しているMCPはタグ管理を直接行うことができませんが、SQLであればタグ変更用のプロンプトを教えてくれますのでコマンドで即実行できます。
まとめ:第二言語学習の外部化がもたらす革新
このClaude MCP×データベースシステムのポイントは、頭の中に蓄積された第二言語の知識を外部化し、AIと連携して柔軟に活用することにあります。
外部化による学習革命
単調な繰り返し記憶からの解放
Ankiなどの方法では「覚える→忘れる→また覚える」の繰り返しでした。しかし外部データベースに蓄積したものを柔軟に出力できるようにすることで、実際の運用スキル向上に集中できます。
特に自分が失敗したうまく言えなかったフレーズを復習するときも、概念や状況を伝えるだけで過去のデータを引っ張り出してくれるので、膨大なデータが蓄積されても引き出すのが容易で無駄になりません。
個人の学習体験の可視化
正解・間違いなどのデータをつけておくことで自分が何を学び、どこでつまずき、どの分野が得意かが明確になります。これまで頭の中で漠然としていた言語学習の軌跡を具体的なデータとして把握できるようになります。自分でコードを組まなくてもLLMを通じて指示するだけでそれができることがこのシステムの利点です。
知識の再活用と発展
蓄積されたフレーズは単なる暗記素材ではなく、新しい表現を生み出すための素材になります。AIが既存の知識を分析し、類似表現や応用パターンを提案することで、学習した内容の拡張が簡単です。
言語学習の新しいパラダイム
従来:「覚える → 使う → 忘れる → また覚える」
新しいアプローチ:「蓄積する → 外部化する → AIと協働する → 応用・発展させる」
MCPとの連携で言語学習が知識の暗記よりも知識の活用と創造的な表現力の向上へとシフトさせることができます。自分の場合はさらにこのデータベースをGoogle text-to-speechを使って音声化し、日々聞き流しながらフレーズの定着を試みてます。今回は一例ですのでぜひ研究者や独学者の皆さんも一度自分に合った方法を探してみてください。
参考リンク・URL
PostgreSQL MCP Server
- @modelcontextprotocol/server-postgres 公式ドキュメント
- PostgreSQL MCP Server GitHub
- PostgreSQL MCP Server (アーカイブ版)
File System MCP
db-mcp-server (multidatabase用)
https://github.com/FreePeak/db-mcp-server


コメント