





AI検索全盛の時代となり、気になる論文や必要な論文がどんどん増えていっているのですが、皆さんはどう管理をしていますでしょうか?
・前に読んだ論文で、こんな感じの内容だったけどイマイチはっきり思い出せない
・あるトピックの内容を大量の論文から横断的に抽出したい
そんなことはないでしょうか?
こういう時に役に立つのは何といってもGoogle Notebook LMのようなツールだと思うのですが、論文を整理するうえで物足りないのは「ソースの数に制限がある」「いちいちアップロードが面倒くさい」「元のPDFファイルをさっと開けない(図や表がみられない)」という点です。
Google Notebook LMはそもそも別に論文用のツールではないので、研究者向けの方向へ発展するのは期待しにくいのではないかと思います。
そこで、ローカル環境で手持ちの全論文を対象にして似たようなツールを作れないか、と思い、今回のツール「PDF Semantic Scan」を作ってみました。
初めはPythonで動かしていましたが、プログラムに詳しくない方でも簡単に使えるようにexeファイル形式でWindows向けexeファイル形式のソフトとして作り直しました。
β版として配布を開始していますので、ぜひ研究者の方に使ってもらえると嬉しいです。
今後需要がありそうであれば、有償化してさらに機能を発展させるようにしていきます。気に入った方は周りの方に広めつつ、機能の支援をして頂けると嬉しいです。
同時に、以前から論文関係のツールを使っていて思うのが、日本発のツールが非常に少ないという事です。ただでさえ、英文校正やら法外な投稿料やら搾取されているように感じるうえ、ツールまでもお金が外に流れていくのかと思うと、何となく悲しみを覚えます。本ツールは英語対応もできるようにしていますので、やはり需要があれば、日本発のツールとして海外含め発展していくことを密かに望んでいます。
基本的な使い方については以下の動画で紹介していますので参考にしてください。
詳細な使い方を含めた説明を以下で書いていきます。
配布方法
現在のところβ版をBOOTHもしくは下記GoogleDriveリンクから無償で配布しています(2025/05/11現在)。


現時点ではまだまだですがもう少し機能が高度になりましたら今後有償化も検討しています。
PDF Semantic Scanの主な機能
このツールはざっくり言うと自分の持っているPDFファイルの文献から質問の答えに合致したテキストを見つけ出したり、自分の持っている文献に基づいて回答を作ってくれるツールです。
主に以下の様なことができます。
- 自然言語を用いたクエリでフォルダ内のPDFファイルのテキストを検索する
- 自然言語を用いたクエリに合致するPDFファイルを類似度順に並べる
- クエリに合致するPDFファイルのテキストから質問への回答を生成する
- クエリに合致するPDFファイル同士の意味的な近さをプロットする
- PDFファイル同士を意味的な近さに応じてクラスタリングする
抽象的かもしれないので具体的な例を書きますと
「アルツハイマー病のリスク因子は?」と書くだけで
1.アルツハイマー病のリスク因子について書かれたテキスト部分を抽出して並べる
さらに書いてあるPDFファイルをワンクリックで確認できる(文献管理ソフトZoteroとの連携も可)
2.抽出されたテキストに基づいて質問に対する答えを作ってくれる
という感じです。論文検索AIなどでよくある機能をローカルで行うようなものとなっています。
使い方の概要
まず使用するには大まかに分けて次の様なステップが必要です。
- PDFの入っているフォルダを選択する
- PDFを200-300wordsのテキストに小分けにして抽出する
- テキストの塊にベクトルを埋め込み、インデックスファイルを作る
- インデックスファイルを使用してAI検索・回答生成・プロットなどを行う
順番に何をするか見ていきます。
1.PDFの入っているフォルダを選ぶ
まずexeファイルをダブルクリックして起動します。
使用言語が英語になっていますので、最初に右側の"Settings"のタブからDisplay languageをJapaneseに変更し、Saveボタンを押します。再起動すると言語が変わります。
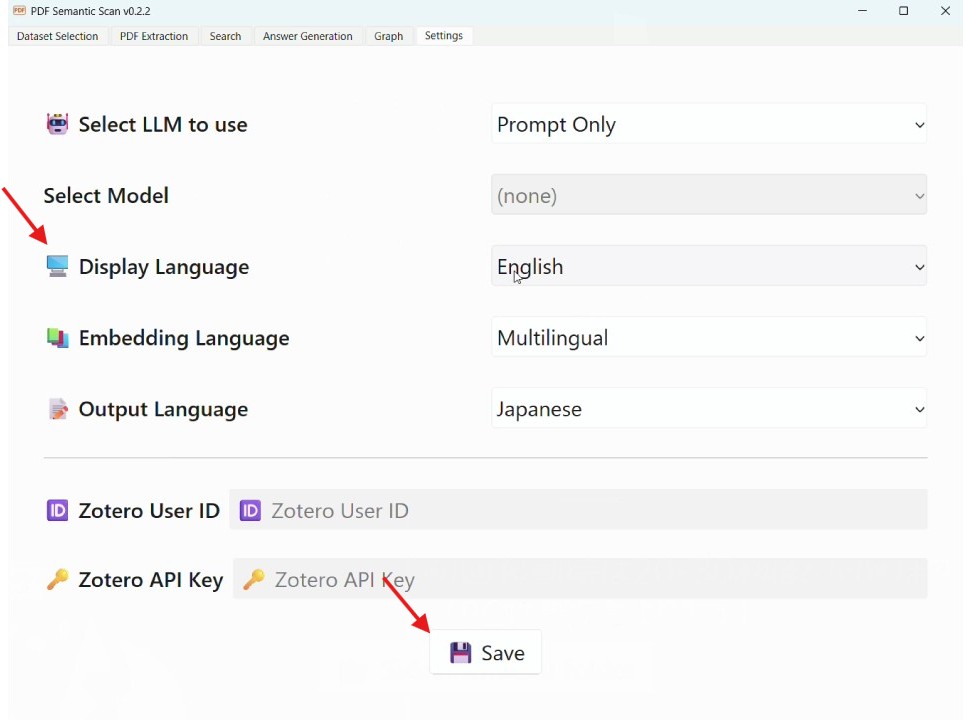
左上のタブにある「データセット選択」を押してデータセットの保存先を選択します。
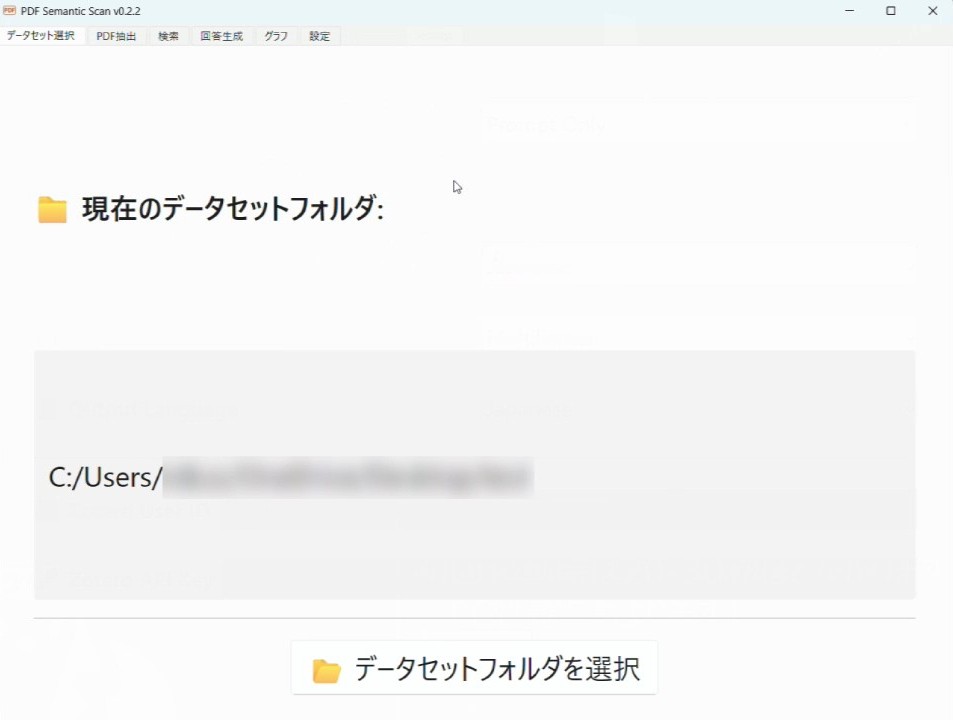
ここで「データセット」というのはPDFから抽出したすべてのテキスト(jsonlファイル形式)や自然言語で検索するためのインデックスファイル(bin, npzファイル形式)を保存しておくフォルダです。
1500本の論文で試したところ1.5GBくらいにはなったので、余裕があるところに入れて置いた方が良いでしょう。
フォルダを選んだら次に「設定」のタブに行きます。
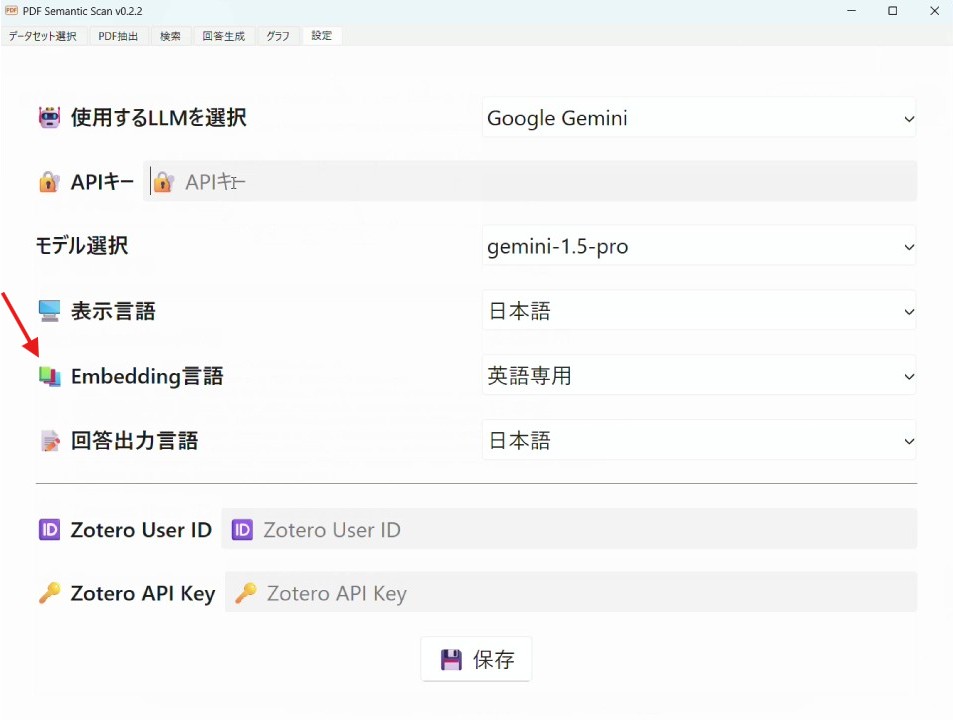
Embedding言語という欄があります。ここで、抽出したい文献で使われている言語に合わせた選択をします。英語の文献がほとんどであれば「英語専用」、日本語や他の言語も多数あるようなら「多言語対応」にしてください。ただ日本語などの文献がわずかで検索にあまり使う予定がないのであれば精度の高さの点から英語専用を選ぶことをお勧めします。
ここで使うEmbedding言語に応じて、テキストに埋め込まれるSentence Transformerのモデルが変わります。このTransformerというのは単語や段落などのテキスト情報の意味をベクトルに変換したもので、大規模言語モデル(LLM)で使われている技術です。今や知らない人はいないChatGPTですが、GPTというのもGenerative Pre-trained Transformerの略であり、Transformerのモデルの一種であることが分かります。
このツールではローカル環境で軽量に動かしたいので英語専用のモデルではall-MiniLM-L6-v2、多言語用のモデルではparaphrase-multilingual-MiniLM-L12-v2というものを使っています。軽量ですが意味の検出では比較的うまく働いてくれているように思います。ちなみにこれらのモデルでは384次元のベクトルを埋め込みますが、新しい言語モデルでは1000~3000次元以上の埋め込みがされており、精度としてはどうしても差が出ます。今後自分のPCの機能が上がってきたり、より良い軽量モデルがあれば改訂・追加していく予定です。
終わったら必ず保存ボタンを押しましょう。
そうしたらタブの「PDF抽出」を選んで、テキスト抽出と埋め込みをします。
「PDFフォルダを選択」のボタンがあるので、そちらを押して抽出したいPDFがあるフォルダを選びましょう。サブフォルダの中にもPDFが小分けされている場合は、「サブフォルダも含める」にチェックを入れておいてください。
これでPDFフォルダの選択までは終了です。
2. テキスト抽出とベクトル埋め込み
次に「段落抽出を実行」ボタンを押しましょう。
すると全PDFファイルからテキストが小分けにされて抽出されます。「データセット選択」で選んだフォルダにjsonlファイルとして保存されます。一応論文の参考文献のセクションは入らないように工夫したのですが、結構入ってしまうことが多いです。
本数が多いとそれなりに時間と負荷がかかりますので、この作業中はあまりPCを他に動かさないほうがいいかもしれません。
続いて「Embedding インデックス更新」というボタンを押すと抽出した段落ごとにベクトルが埋め込まれます。要するにプログラムにも段落の意味が分かるようになる感じですね。
こちらも結構時間がかかります。1500本の論文で概ね20-30分ほどかかりました。PCの性能にもよるとは思います。
これが終わると検索の準備完了です。
ちなみに、文献をフォルダ内に後から追加することがあるかと思います。そんな時は再度「テキスト抽出」「Embedding」を行ってもらえれば追加できるので大丈夫です。2度目の処理の際は、既に読み込んだ文献はスキップするようになっていますので、時間はほとんどかかりません。
逆にフォルダ内のPDFを消した場合は、インデックスやテキスト抽出ファイルの更新はされません。こっちについては実装がやや大変でしたので、あきらめております。もし消した状態を反映させたいときは下の方にある「フル再構築」のボタンを押して元のファイルを削除して作り直すことを推奨します。
3. 自然言語を用いたクエリによる類似度検索
「検索」タブを使うと自然言語で検索をすることができます。
Embedding言語を英語とした場合は英語でのみ、多言語の場合は日本語でも検索が可能です。
新規にインデックスファイルを作った際は読み込みがまだされていないので、必ず「リロード」ボタンを最初に押してください。
クエリをいれるとそれに合致している順にPDFの段落が下に出てきます。先ほどのベクトルを使ってコサイン類似度という指標を導出しており、-1から1まででscoreが出てきます。
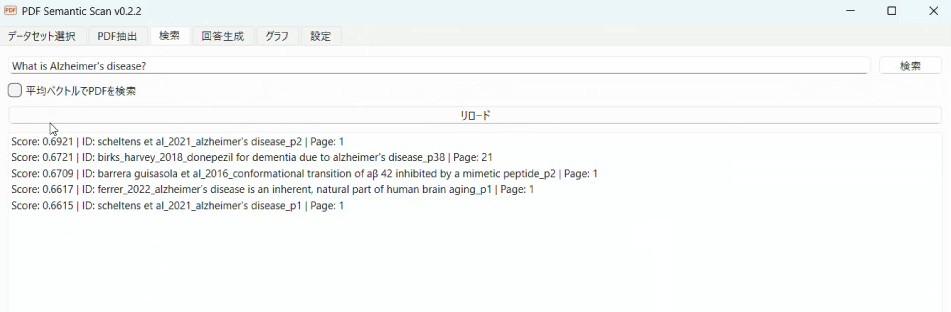
個々の論文をクリックすることで抽出された段落をみることもできます。また、下にある「ブラウザ/Zoteroで開く」ボタンを押すと即座にその論文をチェックできます。
この検索方法ですと内容が合致している段落が多かった場合、一つの論文からの結果が多数出ることがあります。
段落ではなく論文単位でどの論文が質問に合致しているかを調べたい場合「平均ベクトルでPDFを検索」にチェックを入れて検索を行います。
すると、合致度の高い順に論文のファイルが出てきます。
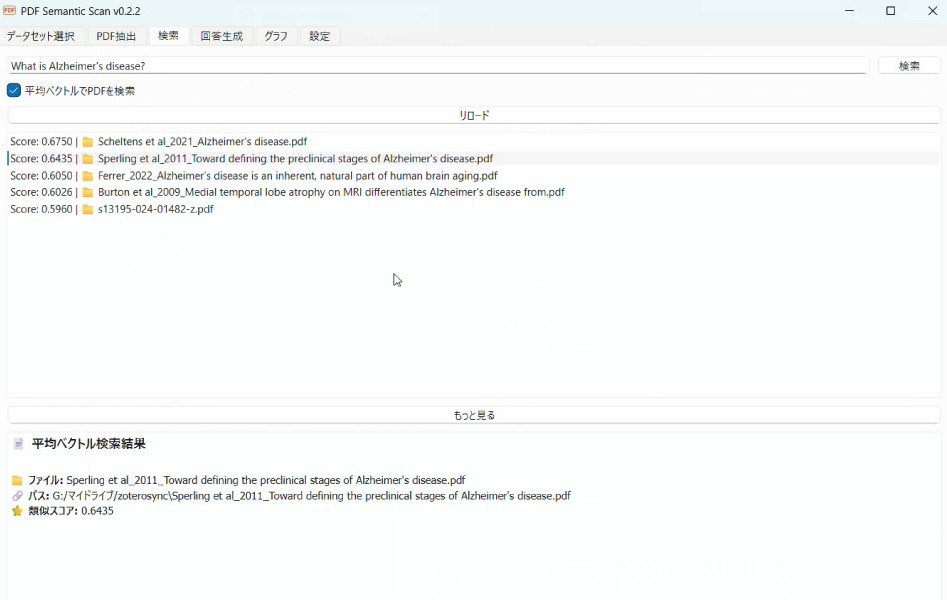
これは各段落に埋め込まれたベクトルのうち、すべての抽出テキストの中から特異性が高い部分に重みをつけて平均化したベクトルを使って検索するようにしたものです。
この検索方法についても「もっと見る」のボタンを押すとより多くの結果をみられます。
4. 自然言語を用いたクエリによる回答生成
続いて「回答生成」のタブをみていきます。
こちらに質問を入れると3の検索と同じアルゴリズムで段落を抽出し、抽出された段落から情報を集めて回答生成がされます。
使用する前に設定画面でどの大規模言語モデルを使うか選択しましょう。
一番お手軽なのは「Prompt-only」です。これは質問して出てきた内容をChat GPTなどの言語モデルでチャットして聞けるようにクリップボードにコピーできる機能です。「プロンプトをコピー」というボタンを押すと以下の様な文章がクリップボードに保存されます。
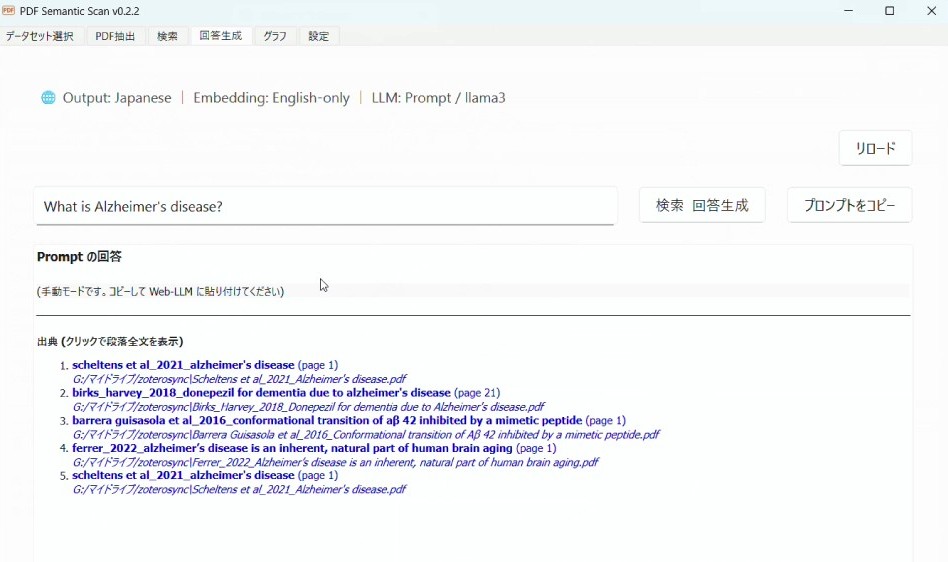
以下の番号付きの文章の一部を参考にして、質問にあった回答を日本語で情報をできるだけ多く抽出し答えてください。
適切な箇所に [1], [2] などで出典を示してください。
[1]...(検索で出てきた段落)
[2]...(検索で出てきた段落)
質問:
回答:
[1][2]のところには実際に検索して出てきた文章が入ります。
これをコピペしてChatGPTやGemini, Grokなどに入力することで、自分の持っているPDFの段落の情報を使って質問に対する回答を生成してくれます。
特別な設定が要らないので楽ですが、言語モデルのレベルによっては段落の情報を無視してくる場合もあります。あとやはり手間がかかります。
そこで、もう少し高度な方法としてAPIキーを使う方法があります。Google GeminiやOpenAIではAPIキーというものをユーザーに発行しており、それを使うとアプリとそれぞれの言語モデルをオンラインでつなげて使うことができるようになっています。


ただし注意点としてAPIの使用は基本的に従量課金制(使用量に応じて課金される)であるので、必ず使用料金のチェックと金額の確認をしておいてください。ここに関しては免責事項にも書いてありますが、自己確認をお願いします。
とはいえ、Geminiは無料枠もありますし、OpenAIも最新モデルで大量にテキストを入れたり出したりしなければそんな金額になることはないのでよほど大丈夫かとは思います、、、。
APIを使う場合は「設定」画面で言語モデルのGoogle Gemini, OpenAIを選択し、言語モデルを選択します。Gemini-1.5-proが無料枠もあって、性能的にもおすすめです。OpenAIではGPT3.5-turboなども入れてありますがちょっとさすがに古いので、指示にちゃんと従えてなかったりします。
設定したら保存を押し、回答生成画面でリロードボタンを押して、表示が変わっていることを確認します。

そして回答生成ボタンを押すと
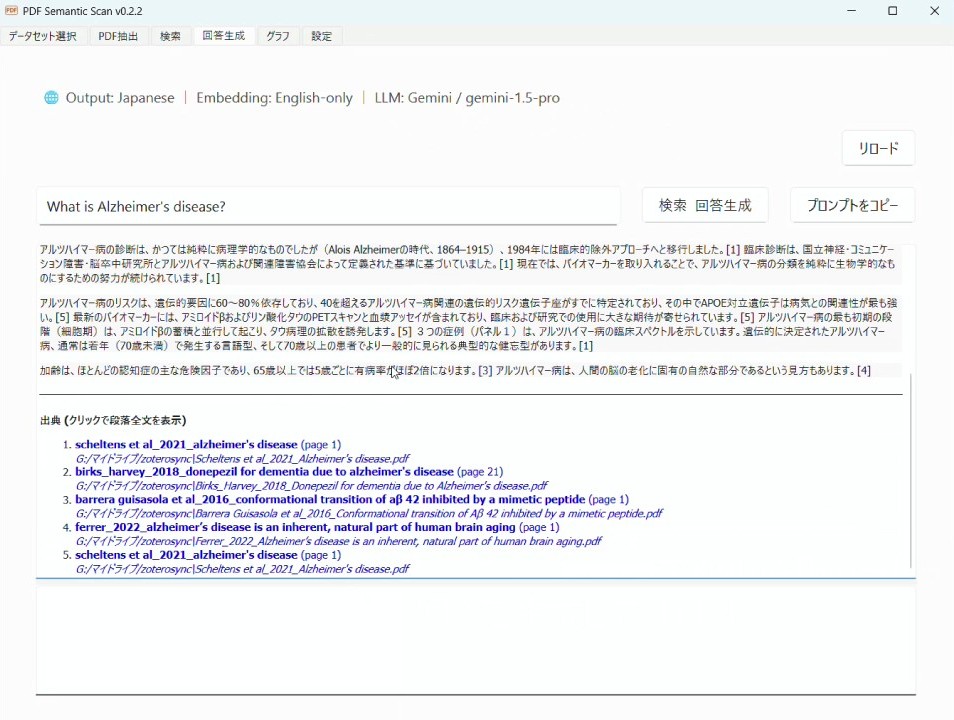
画面に回答が生成されます。
さらにローカル環境で使うOllamaなどを使った場合にも対応できるようにしてみようと設定は作ってありますが、ノートPCで動くようなMistral, Phiあたりでは全然まともにやってくれなかったので、今のところは実用できないレベルです。ローカルでばりばりLLMを使いたい人やオススメのモデルがありましたらまたコメント頂けると助かります。
5. グラフ機能
最後に紹介するのはグラフ機能です。
タブの「グラフ」を選び、まず最初に「座標再計算/更新」というボタンを押します。
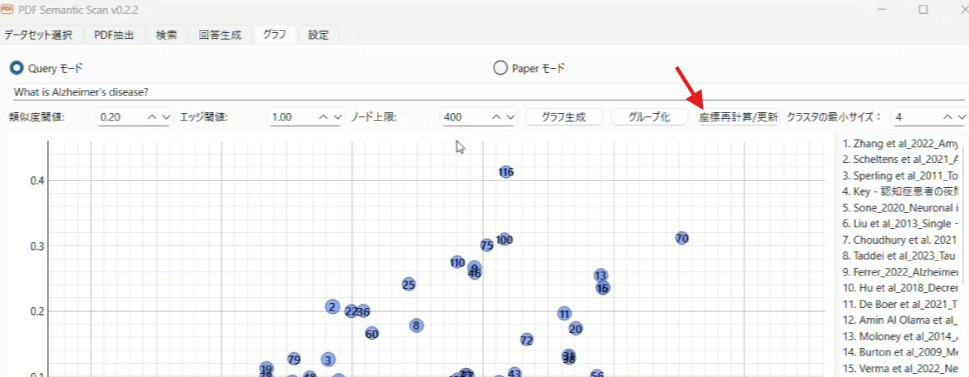
これによって論文ごとの384次元の平均ベクトルが2次元に次元縮約されます。
こうして簡易的ではありますが、論文同士の意味を2次元のプロットで位置関係によって把握することができるようになります。
「グラフ」ではQueryモードとPaperモードがあり、Queryモードでは質問文に合致する論文に絞り込んで、プロット生成します。Paperモードでは自分の手持ちの論文の中から一つを選んで、それに類似する論文に絞り込んでプロット生成します。
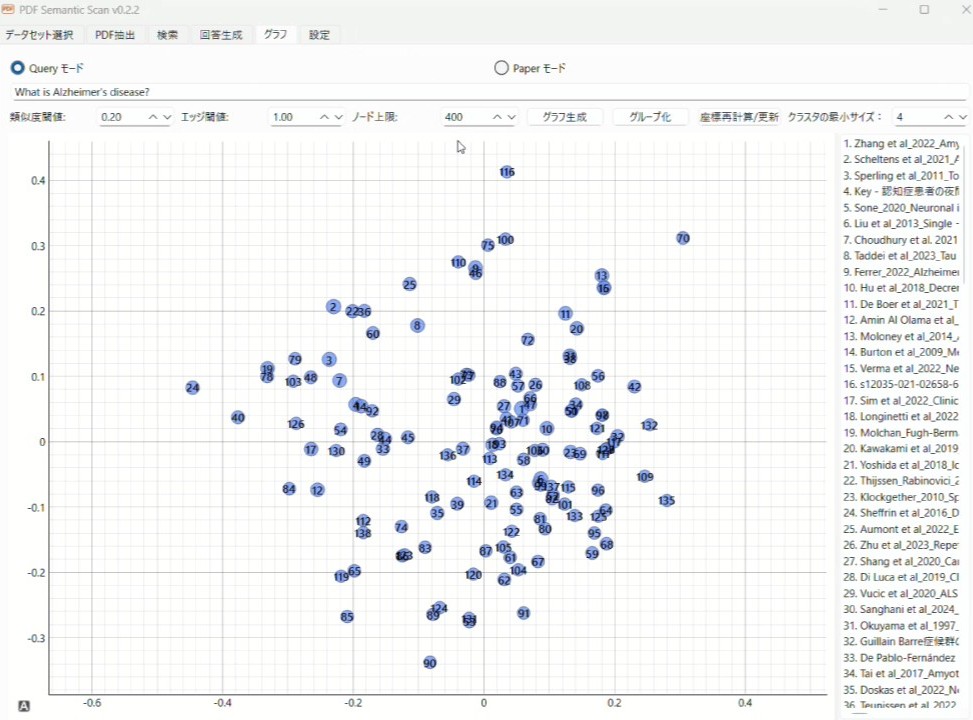
プロット内に文字を入れるのは非常に見にくかったので、それぞれのノードに番号を振り、右側にリストとして提示しています。
論文の意味的な類似度は下にある数値で調整可能で、類似度に応じてエッジ(論文同士をつなぐ線)を表示させたり、表示するノード数の制限をつけたりできるようになっています。
さらにグループ化を押しますと自動的に論文たちのノードを色分けしてクラスタリングします。クラスタ内の文献の最小数も調整できるようになっています。
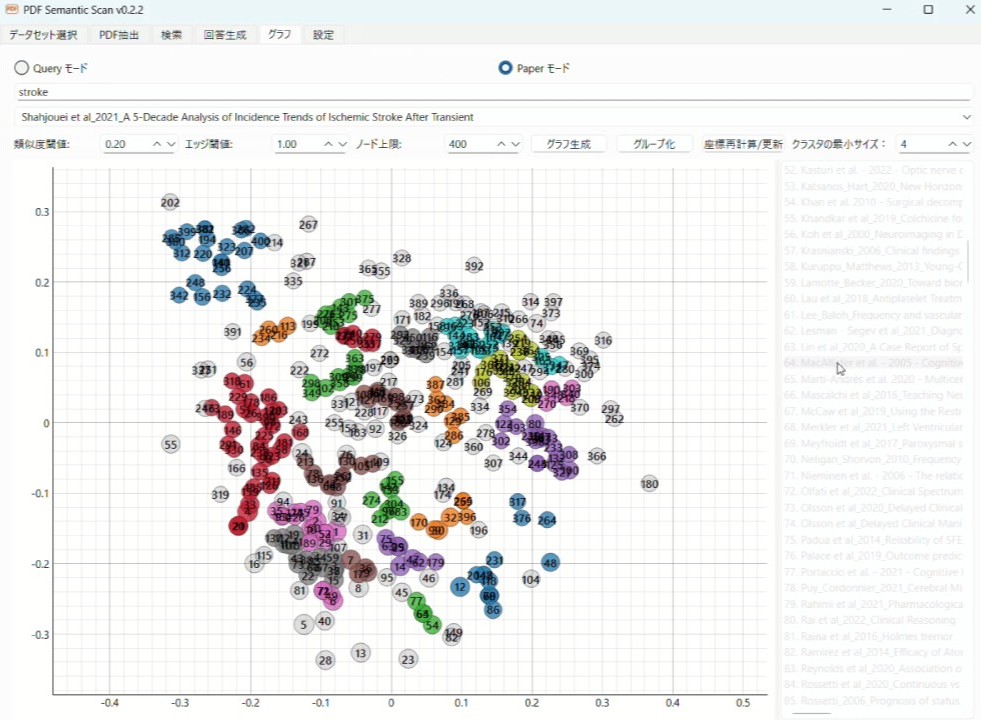
これを行うことで、あるトピックに関連している論文たちが何となくどういう風に集まりを作っているのか眺めることができるようになっています。とりあえず作ってみたのですが、うまくクラスタリングできているときもあれば、違いがよく分からない時もあります笑
まとめ
自作ツールPDF Semantic Scanの紹介をしてみました。
Webアプリ形式のAIツールが氾濫している中ですが、個人的にはむしろ文献が多すぎるのでローカルにで見ていきたいですし、できるだけ中身の構造を把握しながらシンプルなアルゴリズムで使いたい、というところもあり作ってみました。
今回のツールで行っていることの中身は当然把握してますが、半分Vibe-codingですし、大規模言語モデルを専門としているわけでもないので、至らないところが色々あるかもしれません。また今後発展できるようなコメント等頂けますと幸いです。
今後は
・文献を絞って選択し、そこから情報抽出できるようにしたり(要するにNotebookLM的な使い方)
・Zoteroとの連携を強めてタグによる絞り込みやタグの追加/削除などをできるようにする
・検索した文献のPDFをまとめて出力し、楽にNotebookLMに投入できるようにする
などの機能追加がアリかなと思っています。
気に入った方はぜひXやその他SNSなどで広めてみてください。


コメント
これだというものに出会った気がします(本日、試用をはじめたので体験談ではありません)。
tosukeさんが医療界であるのに対し私は法曹界(のうちの司法書士界)であり、環境と状況が違うはずです。私のほうは、①論文よりも書籍であること(自炊本、論文はあるが各別のデータは出回っておらず書籍になって出回ることがほとんど)・②一つのファイルが千頁を超えるものが珍しくなく平均的には400頁であること。ファイル数はまずは800にとどめました。
テキスト抽出に2時間ぐらいかかったかもしれません。
いまEmbedding中でフリーズしています(テキスト抽出時でもフリーズしていたので、放置することにします)。
さっそく使ってみます。
美濃島様
コメント有難うございます。確かに書籍にもお使いいただけますし、現状の埋め込みはローカル環境で無料で使えるもののみにしてますので大量でも一応お使いいただけそうですね。
PC環境によっては相当な時間を要するかもしれませんが、その点は如何ともしがたい部分はありますのでご容赦いただければと思います。
またご感想頂けますと幸いです。