





今回は研究者も知っておきたいAI用語、RAGについて紹介します。
- RAGとは何か?
- RAGを使ったツールの例
- なぜ研究者に必要なのか
- RAGの仕組み
についてざっと紹介しますので、AIを使った効率的な情報収集に興味がある方は是非ご覧ください。
動画での紹介はこちら▼
RAGとは何か
RAGは「Retrieval Augmented Generation」の略です。
- Retrieval(情報の抽出)
- Augmented(拡張)
- Generation(生成)
大規模言語モデルが外部情報を取り込んで、より正確な回答を生成する仕組みです。この手法は2020年にFacebookの研究チームによって提案され、現在では多くのAIシステムで活用されています。
ChatGPT、Gemini、Claudeなどは非常に高精度ですが、専門知識では情報不足で間違える事があります。

専門特化モデルを毎回大量のトレーニングをして作るのは非効率ですが、優秀な汎用モデルに外部情報を参照させれば、コストを抑えつつ正確な回答が得られます。これがRAGの考え方です。
RAGツールの例
実は皆さんが使っているツールの多くがRAGです。
人気のGoogleNotebookLMは個人用RAGで、PDF、音声、テキストファイルから正確な情報を抽出できます。特に引用部分の確認までできるので研究者には有用です。
以前の記事でも紹介しています。
日本からの論文ですがArxivで見かけたpreprintの論文ではGoogleNotebookLMを使って肺がんのステージングを行わせた報告があります。やはりRAGこうした専門知識を用いるのには有用であることが分かります。
また、論文検索AIも論文データベースに限定してLLMが情報を引っ張ってくる、まさにRAGです。こちらも以前まとめていますので、気になる方はこちらをご覧ください。
なぜ研究者に必要なのか
研究者は誰も知らない知見を切り開く仕事です。汎用モデルでは知らないようなことを調べ、整理する必要があります。

そして論文や発表では、根拠となる文献を正確に把握することが必須です。RAGなら大量の情報から引用元を明確にして情報抽出できるため、研究者にとって非常に有用です。
続いてRAGの仕組みをさらっとみていきましょう。
RAGの仕組み
情報の抽出(Retrieval)
まずは情報の抽出です。よくとられる方法の一つは、文章をベクトル(数字の配列)に変換して自然言語検索を可能にすることです。
イメージとしてはこんな感じです。
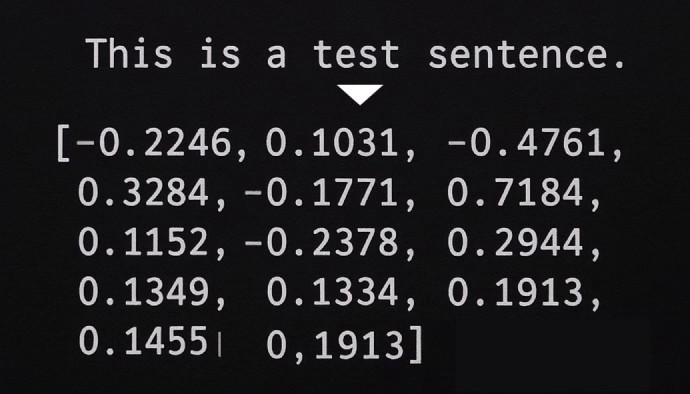
似た内容は近い距離に、異なる内容は遠い距離に配置されます。例えば2次元のベクトルを使って単語に埋め込むとしたらこんなイメージです。単語だけでなく文章単位でもこのようにベクトルを埋め込んで処理することができるため、文章間の違いや類似度を測ることができます。
▼マリオファミリーは近くにあり、ポケモンは少し離れる
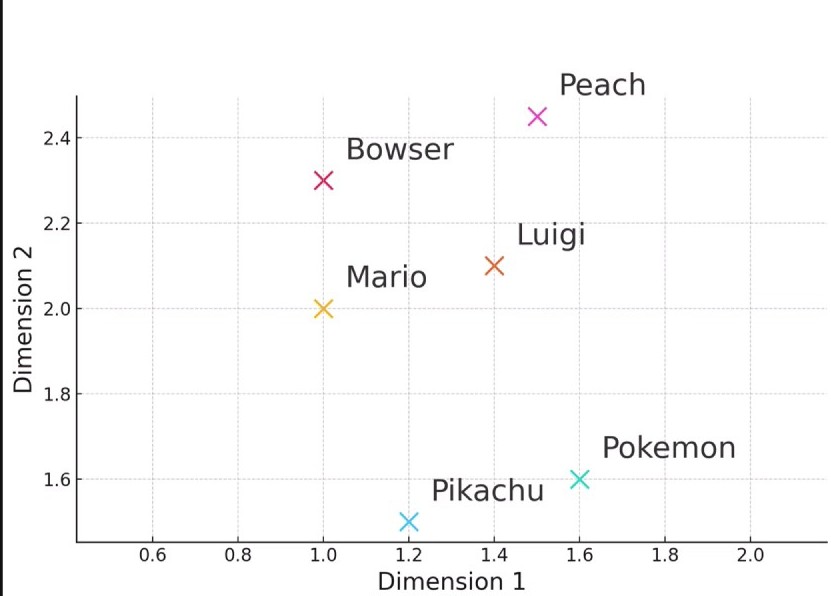
分かりやすく二次元にしてみましたが、実際は超軽量なモデルでも300次元以上の複雑な空間で処理されています。この処理はマシンパワーと容量を要求するので、普通のPCではなかなか容易にできません。
ただ、ChatGPTなどの大規模言語モデルではAPIを使ってインターネットを使ってこの処理を代替することができるので、お金さえ払えばノートPCでも自分のテキストに埋め込みを行うことはできるようになっています。
この作業においては適切な文章量での区切り(チャンク分け)が重要です。PDFのような処理しにくいファイルは、単純に文字数や行数で区切るのではなく、意味を持つ段落単位で分けることが埋め込みにおいて重要です。意味が途中で切れてしまうと、検索精度が大きく低下してしまうからです。
最終的にはこのベクトルを使って質問文と対応する回答文を計算することで、自然な答えを見つけられます。
これ以外にも検索ワードから派生するキーワードをLLMで生成し、それぞれを調べるという方法もあります。例えばSportsと検索したら自動的にBasketball, Baseball, Soccerなどを一緒に検索してしまうという方法です。細かい文脈は分からないですが、幅広い検索を行うことができます。
最近では、ベクトル検索とキーワード検索を組み合わせた「hybrid retriever」という手法も注目されており、実際コードをみてみると多くのRAGで取り入れられています。これにより、意味的な類似性と正確なキーワードマッチの両方を活用できるため、より高精度な情報抽出が可能になります。
ちなみに、Google NotebookLMなどで引用時に文章単位でハイライトがされるのは、この埋め込みの単位(チャンク)ではないかと私は推測しています。適切にチャンク分けされた文書なら、意味のある単位で引用元を示すことができるわけです。
さらにこの後、検索で引っかかった情報をランク付けして渡すことが重要です。どういった情報に重みを置くかはツール毎に調整が異なるため、この優先順位によっても結果が大きく変わります。
生成(Generation)
そして生成の段階です。
抽出された情報をLLMにインプットし、まとめて回答を生成します。LLMの内部知識をどこまでブレンドするか、プロンプトの内容、インプットの情報量の調整で結果が大きく変わります。
例えばScispaceやChatGPTを比較するとScispaceでは基本的に論文に書いてある知識を主に使うのに対して、ChatGPTのほうが内部知識を使う割合は多いです。
(左:Scispace, 右:ChatGPT)
論文からの情報を重視したい場合はScispaceの方がいいですし、より一般的な知識を聞きたいならChatGPTですね。
他にもinputの情報量によってもアウトプットの内容や量は変わります。最近紹介したAI論文検索ツールの中ではAnswerthis AIは非常にインプット量が多く、回答の量も多くなっています。
生成の過程においても内部モデルによって結果が大きく変わると思います。
ただ、論文などを書く研究者にとっては正確性を重視してくれる方が望ましく、書いてないことは書いてないときちんと言ってくれるモデルがいいですね。その点NotebookLMはやはり優秀だと思います。
何をどのように優先すべきかということについては以前の記事でもまとめていますのでこちらもまたご覧ください。
まとめ
- RAGは大規模言語モデルに外部情報を取り込んで高精度な出力を実現する仕組み
- 専門知識を扱う研究者には最適なツール
- 前処理、抽出、優先付け、生成の各プロセスで結果が大きく変わるため、処理内容を理解して使うことが重要
ちなみに私は最近ClaudeとObsidianの連携にハマっており、論文やメモの情報をClaudeで処理させています。めちゃくちゃおすすめなので、また次回紹介します。


コメント