





※英語で書いた記事をClaudeを用いて日本語訳したのち、自分の手で修正を加えています。
この記事では、研究論文における核となる「問いと主張」について見ていきます。
前回の記事はこちら:

研究論文を書くプロセスにおいて、まず最初にやるべきことは、中心となる問いと、それに答える主張を絞り込むことではないでしょうか。たまにアカデミックライティングの本に「まずイントロダクションから書き始めるとよい」と提案しているものもありますが、個人的にはイマイチ同意できません。以下で詳しくみていきます
最初にやるべきことは主張を明確にすること
今の研究論文の目的は、とにかく読者に明確な主張を伝えることです。昔の研究論文をみると、研究の過程を細かに記録し、データを発見した順に提示する記述的なスタイルが多くみられます。しかし、このスタイルは現代の読者にはもう適していません。毎年何百万もの論文が出版され、PubMedだけでも年間100万本以上がインデックスされています。すべての論文を最初から最後まで読む余裕のある研究者は基本的にいません。だからこそ、研究の主張を最初に明確にし、そのメッセージがすべてのセクションを通じて一貫していることを確認する必要があります。
この点をよく示す例が、有名なメンデルの『Experiments on Plant Hybrids』(英訳版)です。興味深いことに、この論文は現在私たちが使っているIMRAD構造に概ね従っています。先行研究をレビューし、方法を説明し、結果と考察を述べるという流れです。しかし決定的な違いは、主張の核心である分離の法則と独立の法則が論文の中盤まで登場しないことです。冒頭の「序論的所見」では「詳細な実験」が必要だと述べるだけで、実際に何が発見されたのかは示されていません。現代の論文であれば、この核心的な発見はアブストラクト(と場合によってはイントロダクションの末尾)に登場するはずです。実際、メンデルの画期的な研究は30年以上もほぼ無視されていました。その原因はさまざまですが、主張の核心が論文の奥深くに埋もれていたことも、見過ごされた一因だったかもしれません。
この例が示す現代の論文との違いは、今日ではさらに重要になっています。多くの読者は論文を斜め読みしたり、LLMを使って要約したりしています。すべてを読む時間がないからです。それを踏まえると主張は冒頭から明確であるのが望ましいです。もし主張が中に埋もれた論文をLLMが要約したら、最も重要なポイントを見落としたり歪めたりするかもしれません。人間の読者がそこにたどり着く前に読むのをやめてしまうのと同じです。なので、書き始める前にまず主張を明確にし、それが論文の冒頭部分からきちんと見えるようにすることが最も大事だと考えます。
LLMを活用して構成要素を集め、整理する
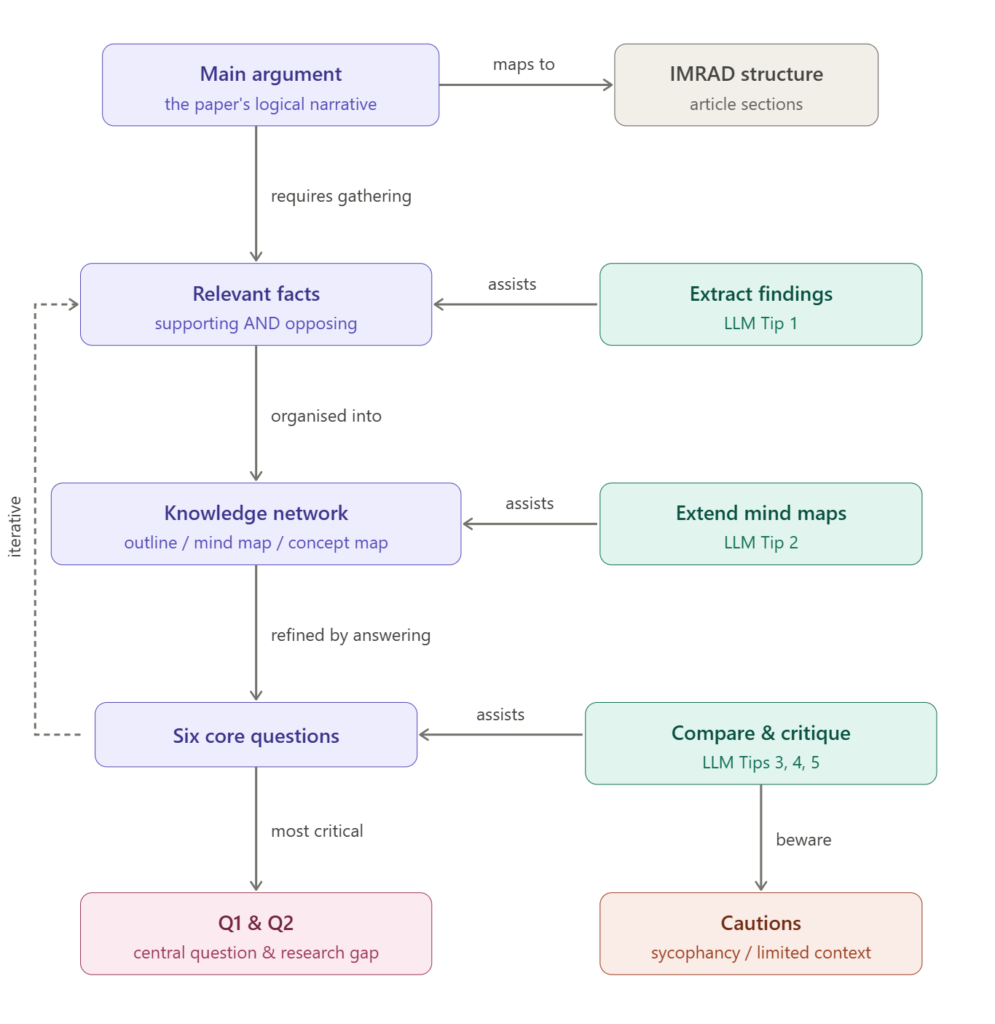
しっかりとした主張を組み立てるには、いくつかのステップを踏む必要があります。①先行研究や自分の研究結果から関連する事実を選び出し、②それらの間の関係を見つけ、知識のネットワークを構築し、③最終的にそのネットワークの中から論理的な順序で語るための明確な道筋を見出す、という流れです。ここでいう「主張」とは、単なる結論のことではありません。論文全体を貫く論理的なストーリーのことです。つまり、どんな問いを立てたのか、なぜそれが重要なのか、何が見つかったのか、そしてそれが自分の研究を超えてどんな意味を持つのか、ということです。このセクションでは、それぞれのステップを順に見ていきます。
事実の選択はチェリーピッキングではない
最初のステップである「事実の選択」は、科学論文で最も批判される行為のひとつであるチェリーピッキングのように聞こえるかもしれません。しかし、ここで私が言いたい選択というのは本質的に異なります。チェリーピッキングとは、望む結論を裏付ける事実だけを選び、都合の悪い証拠を無視することです。そうではなくて、ここでやるべきことは、主張に関連する事実を、賛成・反対の両方を含めて選び出し、主張をより精緻かつ具体的なものに磨き上げることです。これには、主張の限界を特定し、次の研究課題につなげることも含まれます。弱点を隠して主張を強く見せるのが目的ではなく、弱点を認め対処することで、真に強い主張にすることが目的です。
関連する事実の集め方
では、事実はどこから集めるのでしょうか。ひとつの方法は、以前の記事で紹介したAIリサーチツールを使って、関連するエビデンスを検索することです。
これらのツールの多くにはセマンティック検索機能が搭載されているので、自然言語で質問するだけで検索できます。関連する知見を集めたら、執筆に取りかかる前に整理しておきましょう。私はこういう場合ZoteroとObsidianを使っています。

LLMの使い方例① — 知見の抽出はLLMに、解釈は自分で
論文から重要な知見を抽出することは、今ではLLMが確実にこなせる作業です。しかし、それらの知見をご自身の研究の文脈で解釈することは、LLMにはまだ難しい部分です。論文を読む際には、単にその論文を要約するのではなく、知見が自分の研究とどう関係するかをメモすることに集中するのがオススメです。そうすることで、後のステップが格段にやりやすくなります。
事実の整理方法
関連する事実を集めたら、それらとその関係性を体系的に整理します。整理の方法は個人の好みとプロジェクトの規模によります。アウトライン、マインドマップ、コンセプトマップなど、さまざまな方法があります。プロジェクトの規模が比較的小さく、関係性が頭の中で明確であれば、シンプルなアウトラインだけで十分かもしれません。アウトラインはそのまま論文のパラグラフ構成に直結します。結果や先行研究の間の関係を解きほぐす必要がある複雑なプロジェクトでは、マインドマップやコンセプトマップのような視覚的なアプローチのほうが効果的です。
LLMの使い方例② — LLMが生成するマインドマップを出発点に
マインドマップはアイデアの発想と整理の両方に有用で、多くのLLMベースのツールがこのフォーマットを提供しています。たとえば、Google NotebookLMはソースを要約するマインドマップを生成できます。
LLMが生成したマインドマップと、自分で描いたマインドマップを組み合わせることもできます。また個人的には手描きで紙に発想をまとめながら、写真に撮ってLLMで作成するのも好きです。LLMの出力はあくまで下書きや出発点として扱い、そこに自分の思考を加えて発展させるのがオススメです。

コンセプトマップの活用
もうひとつの選択肢はコンセプトマップです。見た目はマインドマップに似ていますが、決定的な違いがひとつあります。概念間のつながりに動詞やフレーズでラベルが付けられており、関係性が明示されている点です。
難点として日本語の場合は助詞を含めないと関係性が分かりにくい一方で、助詞だけを矢印に載せても意味が取りにくいというところがあります。基本的にこの方法をとる場合は英語でまとめておくのがオススメです。
これにより、概念同士がどう関係しているのかを曖昧なままにせず、明確に言語化することが求められます。この明確さは、次のステップでLLMを使って主張を構造化する際に特に価値を発揮します。曖昧なつながりよりも、明確に定義された関係性のほうが、はるかに正確なコンテキストをLLMに提供できるからです。
LLMを使って主張を磨く
コンセプトどうしのネットワークができたところで、それをどうやってLLMを使って一貫した主張に磨き上げるのでしょうか。まずは最終的なゴールを設定します。以下のリストは、研究論文を書く際に答えるべき核心的な問いで、 The Scientist's Guide to Writing から引用したものです(洋書ですがこの本はかなりオススメです)。
- 中心となる問いは何か?
- なぜこの問いが重要なのか?
- この問いに答えるためにどんなデータ(変数)が必要か?
- そのデータを得るためにどんな方法を使うか?
- データから問いに答えるためにどんな分析が必要か?
- どんなデータ(値)が得られたか?
- 分析の結果はどうだったか?
- 分析は中心の問いにどう答えたか?
- この答えは、より広い分野に何を教えてくれるか?
各問いに答えることで論文の核となる内容が明確になり、それぞれがIMRAD構造のセクションに対応しています。主張の構築に焦点を当てる場合、特に重要なのはこのうちの1,2,3,7,8,9の6つです。残りの3つ(Q4、Q5、Q6)は、執筆に取りかかる時点ですでに決まっている(実験は終わっているため)か、他の6つが整えば自然と決まります。コンセプトネットワークを見ながら、この6つに答えていきます。
- 中心となる問いは何か?
- なぜこの問いが重要なのか?
- この問いに答えるためにどんなデータ(変数)が必要か?
- 分析の結果はどうだったか?
- 分析は中心の問いにどう答えたか?
- この答えは、より広い分野に何を教えてくれるか?
Q1とQ2が特に重要な理由
このうち、Q1とQ2が特に重要です。Q2は研究のギャップと研究の意義に対応しており、これが論文全体の運命を実質的に決めます。実は私自身、現在ある論文の出版に苦戦しています。私の研究は学際的なのですが、中心の問いを関わる分野のひとつだけに偏った重要性に基づいて構成してしまいました。そのため、他の分野の査読者にとっての説得力が弱くなってしまったのです。振り返ると、問いの重要性が自分の研究が関わるすべての分野でどう受け止められるかを、もっと慎重に考えるべきだったと思っています。
リサーチギャップの特定にAIツールを活用する
研究のギャップを特定するのに役立つAIツールもいくつかあります。Scispace、AnswerThis、Jenni AIなどです(Jenni AI以外はブログ内で記事にしています)。


ギャップの発見には有用ですし、ChatGPT、Gemini、Claudeなどの汎用LLMもディープリサーチ機能を使って同様のことができます。ただし、これらのツールは自分の具体的な状況を完全には理解できません。たとえば、研究のギャップが存在しても、必要なデータが手に入らない、必要な機器にアクセスできない、あるいは単に予算がないなど、自分ではそのギャップを埋められない場合もあります。また、提案が理論的に問題があったり、文献の部分的な解釈にしか基づいていなかったりすることも多々あります。なので基本的には、LLMだけに頼るのではなく、自分の研究環境における制約条件やドメイン知識とLLMが提供するアイディアを組み合わせて、意味のあるギャップを見つけ、その意義を明確にする必要があります。
反復的なプロセスを受け入れる
コンセプトネットワークから中心の問いとその答えを最初に選んだとき、それを裏付けるために追加のデータが必要だと気づくことがよくあります。ここで上記のプロセスを反復する必要が出てきます。この時に重要なのが集めてきた事実やコンセプトのネットワークを上述のように整理しておくことです。再び検索し、中心の問いと答えが妥当かどうかを確認し、ネットワークを再構築できるのです。基本的にこのプロセスは直線的ではなく反復的です。何度も立ち戻り修正しながら進みます。
LLMの使い方③ — 自分の答えとLLMの答えを比較する
この反復プロセスにおいて、LLMは特に役立ちます。中心の問いとその答えが決まると、自分ひとりでは別の選択肢がなかなか見えなくなりがちです。しかし、中心の問い、答え、裏付けとなる結果をLLMに聞くために整理すると、その時点で考えていなかった別の視点や問題に気づき始めます。これは、よくある人に聞くときの経験と似ています。自分の意見を誰かに説明すると、自分の考えが整理され、再考を促されるのです。核心的な問いを言語化してLLMと議論することも同じように機能します。見落としていた側面が浮かび上がってくるのです。
もちろんそれだけではなくて実際にLLMに聞いてみることもアイディアを広げるうえで有用です。具体的には、上記の6つの問いに対して自分の答えを書いた後、同じコンテキスト(要約した結果やデータ)を使ってLLMにも同じ問いに答えてもらいます。2つの答えを比較し、それぞれの長所と短所を検討し、良いアイデアを自分の答えに取り込みましょう。これにより、主張がより堅牢になります。
一貫性の確認を怠らない
この6つの問いに繰り返し立ち返ることは、一貫した主張を維持するために不可欠です。私は以前、勢いに任せて論文を一気に書き上げて投稿したことがあります。すると査読者から、「主張を裏付けるデータがあまりにも弱く、論文中のエビデンスの大部分は別の、それほど重要でない主張を支持しているだけだ」と厳しく指摘されました。当然、その論文はリジェクトされました。この経験から学んだのは、主張とそれを裏付けるデータの整合性を確認する作業は、最後だけでなく執筆プロセス全体を通じて繰り返し何度も行うべきだということです。
LLMの使い方④ — LLMを各分野の批評者として活用する
LLMを批評者として使い、核心的な問いについて少なくとも一度は議論することで、私がやらかしたような問題を防ぐことができます。有益な批評を引き出すには、自分の主張やデータ以外にもプロンプトにコンテキストを与えることが鍵です。具体的な役割を割り当てることも重要です。たとえば「あなたは理論物理学者であり、理論物理学ジャーナルの編集者です。その立場から、主張とそれを裏付けるエビデンスを批評してください」というようにします。
LLMの使い方⑤ — LLMにエビデンスの優先度を付けさせる
主張が明確に把握できていないと、冗長な内容を書きがちです。私は研究論文を書き始めた頃、査読コメントで「冗長」という言葉を何度も目にしました。というか、今でも時々指摘されます。この問題には文法的な側面と内容的な側面がありますが、ここでは内容面に焦点を当てます。
コンセプトどうしのネットワークがしっかり構築されていれば、LLMは不要なコンテンツの削ぎ落としにも役立ちます。中心の問いとその答え、そしてデータに対するご自身の解釈の要約を与えたうえで、「中心の問いへの回答に関連する解釈を選び出し、優先度順にランク付けして理由を示してください」と尋ねましょう。出力を確認し、何を残して何を削るかは判断します。やはりここは自分で判断するのが重要です。
LLMを使う際の注意点
このプロセスでLLMを使う際には、いくつか気をつけるべきことがあります。
おべっか(Sycophancy)に注意
批評を得ることは、論文の問題点を見つけるために不可欠です。しかし、LLMの「おべっか」は最近特に問題となってきています。LLMは基本的にユーザーに安易に同意しがちです。なぜなら、結局のところLLMはユーザーに満足してもらい課金を継続してもらうことを目的とした商用サービスだからです。論文の執筆と投稿というストレスフルで消耗するプロセスの最中に、同意してもらえるのは心が揺らぎます。しかし、その甘い言葉がリジェクトという厳しい結果につながることは十分にあります。プロンプトを書く際は、主張の弱点を明示的に指摘するよう求める形にしましょう。LLMが「この段落は論理的に明快で根拠もしっかりしています」と言ったとしても、論文がアクセプトされるまでは鵜呑みにしないでください。
コンテキストの限界を意識する
LLMは具体的な改善提案をしてくれることが多いですが、それを無批判に受け入れるのもリスクがあります。研究論文には膨大なコンテキストが関わっています。データや先行研究だけでなく、実験機器、予算、データへのアクセス、時間的制約といった制約条件や業界内の暗黙の了解もあります。これらすべてをプロンプトに盛り込むことはできませんし、会話が長くなると、蓄積されたコンテキストがLLMを混乱させ始めることがあります。修正を重ねた長いやりとりの後ではハルシネーションが起きやすくなります。こうした限界は常に念頭に置いておくべきです。
まとめ
研究論文を書くには、まず主張を明確にし、次に関連する事実を集め、アウトライン・マインドマップ・コンセプトマップなどを使ってそれらの関係性を整理します。6つの核心的な問いに答えながら、必要に応じて反復的に主張を磨き上げていきます。LLMは各段階をサポートしてくれます。論文からの知見の抽出、アウトラインやマインドマップの生成・拡張、特定の分野の視点からの批評、そしてエビデンスのランク付けによる冗長性の削減などです。ただし、解釈と最終的な判断は必ず自分で行う必要があります。LLMは過度に同意しがちですし、自分の研究の全コンテキストを把握することは不可能だからです。

コメント