





みなさんこんにちは。tosukeです。
AIを使って論文検索、情報整理をしようとしても「ツールが多すぎて、結局どれをどう使えばいいのか分からない」という声をよく耳にします。実際、生成AIを含む研究支援ツールは急速に増えており、すべてを試すのは現実的ではありません。
そこで本記事では、個々のツールの特徴を暗記するのではなく、ツールを“抽象的な構造”として理解することで整理できる方法を紹介します。仕組みを一段上の視点で捉えることで、今後どれだけ新しいサービスが出てきても迷わなくなります。
動画での解説はこちら
AIツール多すぎ問題
論文検索のツールに限らずAI、特にLLMを使ったモデルは雨後の筍の如く大量に存在しています。生成AIを組み込んだツールが増えている背景には次のような要因があるのではないでしょうか。
- LLMが現在情報処理の中心に位置づいている
- LLMがあらゆるデータ形式に対応可能
- “AIを載せれば価値がある”という市場構造
まだまだ多くのAIツールが発展途上であることを踏まえると、この状況は当面続くと考えられます。そのため、ツール名や機能を覚えるのではなく、分類の軸を持つことが重要です。
ツールを構造で理解する
ツールの整理には、
インプット(何を情報源として扱うか)
アウトプット(どのような形で結果を返すか)
この2点だけに着目します。
例:汎用LLM(大規模言語モデル)の場合
ChatGPTなどの汎用的に使われるLLMについて考えてみましょう。
インプットの範囲
- ユーザーからの質問
- 学習データ(大量のテキスト)
- 必要に応じてウェブ検索や論文情報
アウトプットの特性
- テキスト
- 表、要約、説明など柔軟
つまり、インプットが広く、アウトプットも自由度が高いという構造になります。
例えば「ChatGPTの学習データは何からできているの?」という質問をした場合、下図のように表にしてまとめてもらったりすることもできます。

▲例:ChatGPTの学習データの由来について表でまとめてもらった場合
例 : 論文検索特化ツール
では続いて比較対象としてConsensus, Scispaceなどの論文検索特化AIツールで考えてみます。
インプットの範囲
- 論文データベース
- アブストラクト
アウトプットの特性
- テキスト回答
- 論文メタ情報(引用数、研究デザインなど)
特徴は、インプットが限定されている一方で、アウトプットが研究者向けに最適化されていることです。アウトプットはテキストでの回答に加えて表や論文の情報(引用数やジャーナル、研究デザインなど)も同時に得られます。
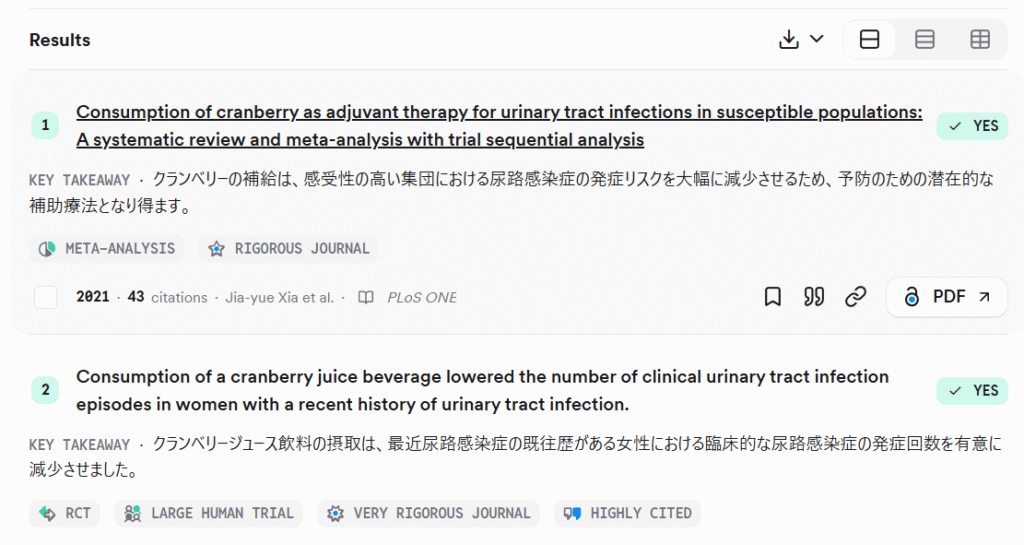
▲例:Consensusでは分かりやすく試験デザインや引用の多さがアイコンで表示されます
アウトプットの情報が見やすく個々の論文の内容についても概要を得ることができ、またツールによってはライブラリに保存したり、Zoteroなどの論文管理ソフトと共有もしやすくなっています。
実際、質問で出てくる論文についてはChatGPTでもこれらの専用ツールでも正直あまり差異がなくなってきているようには思いますが、出力形式が研究者に使いやすい形にチューニングされているというのがこれらの論文検索専用ツールの利点だと思います。
逆に言うと論文以外のウェブでの情報も欲しい場合や、出力形式に柔軟性を持たせたい場合などは汎用LLMの方が便利なわけです。
こうして比べてみるとインプットの部分は汎用LLMの方がカバー範囲が基本的に広く、実は汎用LLMだけで十分なのではないか、とも言えます。これは汎用LLMの機能が拡張されているためというところも大きいでしょう。
となると、論文検索特化ツールについてはアウトプットに強い魅力を感じる部分がなければ無理に使う必要はないと言えます。
このように何をインプットしてほしいのか、何をアウトプットで得たいのかでツールを使い分けると自ずと自分が使いたいツールが見えてくるのではないでしょうか。
他のツールも同様にインプットとアウトプットをまとめてみると下表のようになります。
| Ex. | Input | Output |
|---|---|---|
| ChatGPT | パブリック論文データ・ウェブ、学習データ | 回答など |
| Consensus | パブリック論文データ | 回答+表+リスト |
| NotebookLM | ユーザーが選択したデータ | 回答など |
| OpenEvidence | 質の高い論文・ガイドライン | 回答 |
Google NotebookLMは自分が絞り込んだ論文などデータを絞り込んで使うことができますし、OpenEvidenceのようなツールはハイインパクトな雑誌のレビューやガイドラインなどキュレーションされた論文に絞って回答を出力します。これらについては以下の記事で紹介しています。


これらのツールはインプットとアウトプットの独自性が高く、汎用LLMとは異なるため、代替しにくい存在です。そのため、汎用LLMとは別で使い分ける価値が比較的高いと言えるでしょう。
このようにインプットとアウトプットがこれまでのツールとどう違うかに着目すれば、毎回新しいツールをなんでも試したり飛びついたりする必要もなくなると思います。
ツールの使い分けの例
では実際論文検索や整理をするときにこれらをどう使い分けるのか。
一つの例として論文を調べる時の対象の範囲をどこまで広げるか、という点で使い分けを考えると分かりやすいと思います。
インプットの範囲を考えると汎用LLMがウェブサイトから論文まで最も幅が広く、Google NotebookLMは自分がアップロードした論文のみですので、最も幅が狭いと言えます。先ほど例として出したツールを再度見てみますと下図のようにまとめられます。
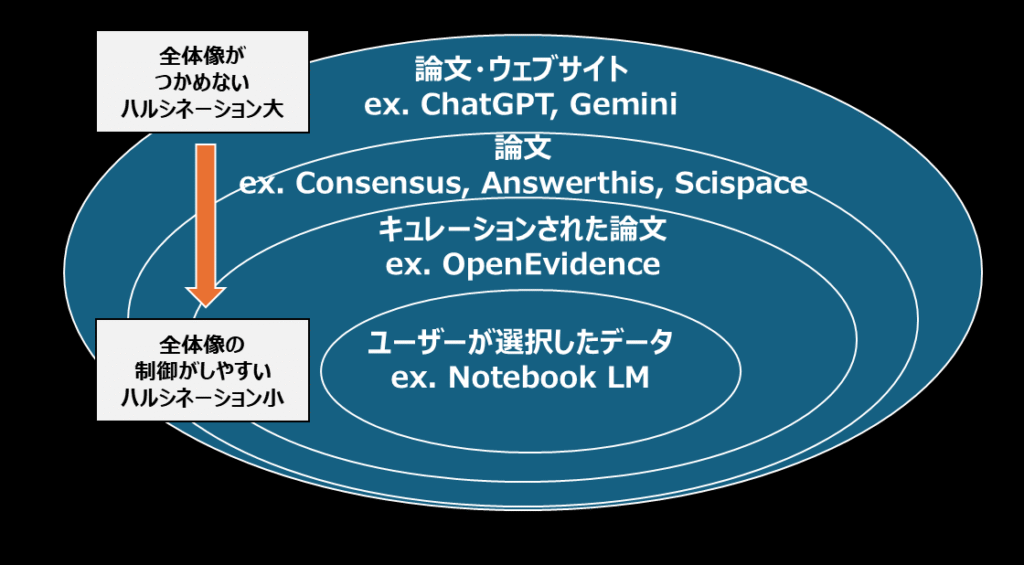
例えば先行研究を調査していくときに、最初に調べる時はできるだけ幅広い情報を調べたいのではないでしょうか。最初から論文を絞り込むのはなかなか難しいですし、見落としている情報があると後から取り返しがつかなくなります。実は自分のやろうとしている研究が既にやられていたものだったら泣けますね。
そのため、最初に調べる時はできるだけ幅広い対象から検索します。つまり、汎用LLMや論文検索専用ツールで論文を調べていきます。
例外的ですがOpenEvidenceのようなツールは医学系に限りますがpaywallを超えた先にある論文(有償論文)からも情報をとれますので、こういったツールが自分の分野で今後出てきたら併用するのが良いでしょう。どうしても汎用LLMで調べられる情報はオープンアクセスに偏りがちです。
対象範囲が広いと、LLMがどこからどのように情報を取っているかがよく分からなかったり、ハルシネーションが起きるリスクもありますが、あくまで初期段階での情報収集と割り切って、幅広い情報の収集をします。
続いて先行研究の概要が把握できた時には、NotebookLMのような情報源を絞り込んだLLMが有用です。LLMの回答が引用している論文を直接参照できるため、ハルシネーションのリスクも低く、自分の確認によって正確性の担保ができるからです。実験計画を立てたり、研究目的を絞り込んでいく場面では正確性が重要視されますので、そういった段階で有用だと思われます。
このようにインプットとアウトプットの出力をイメージしながらどれを使うかを選択していくのがツールを使い分けていくときの肝になると言えるでしょう。
まとめ
- ツールは インプットとアウトプット で整理できる
- インプットが広いほど情報収集向きだが精度管理が必要
- インプットが狭いほど確認や深掘りに向く
- ツール名を覚える必要はなく、抽象構造の理解が本質
この視点があれば、生成AI時代の論文検索に振り回されなくなります。ぜひ今使っているツールも、この軸で見直してみてください。


コメント